📝 Paper Summary
Interpretability
Language Model Pre-training
By manipulating pre-training data and tokenizers, this study reveals that language models acquire character-level knowledge through two distinct mechanisms: statistical artifacts of subword merge rules and semantic associations between word forms and meanings.
Core Problem
Language models are trained on subword tokens and never explicitly see character-level supervision, yet they surprisingly learn spelling and character composition.
Why it matters:
- Understanding this mechanism is crucial for explaining how models handle tasks like rhyming, punning, or spell-checking without explicit character input.
- Prior work demonstrated *that* models learn characters but failed to explain *how*, leaving a gap in understanding the role of tokenization versus semantic learning.
Concrete Example:
A model knows the token 'apple' contains the character 'p', even though 'apple' is a single atomic integer ID to the model. It is unclear if this is due to seeing 'ap' + 'ple' elsewhere (tokenization artifacts) or associating the concept of apple with its spelling (semantic association).
Key Novelty
Causal Disentanglement of Character Acquisition Factors
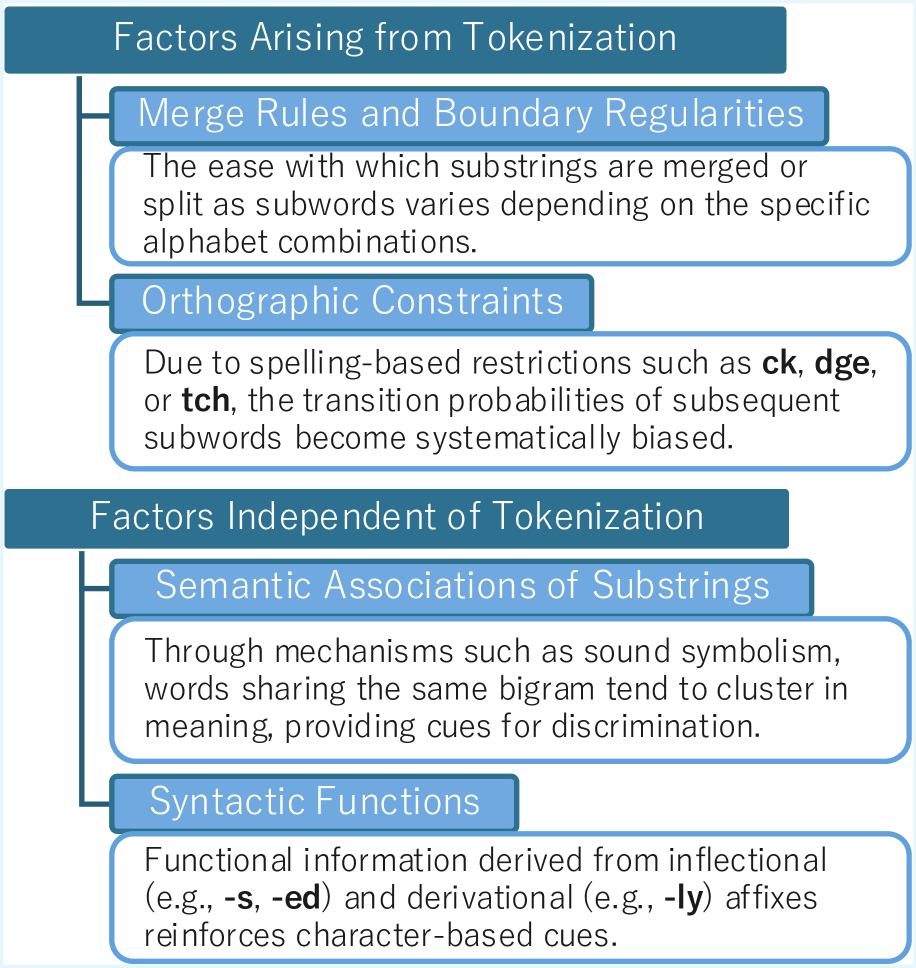
- Isolates factors by pre-training LMs on transformed corpora: 'WordSub' (random strings replacing words to remove semantic links) and 'CharPert' (random character replacement to remove orthography).
- Designs a 'controlled tokenizer' with explicit merge rules to mathematically prove how merge priority orders leak character adjacency information into subword statistics.
Architecture
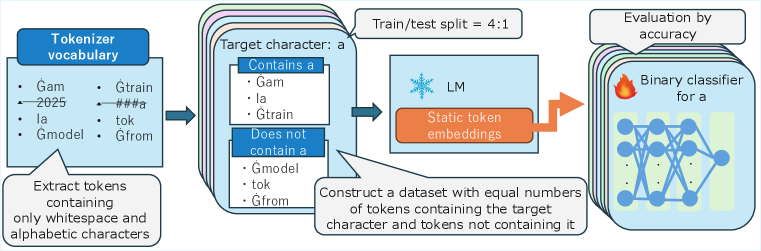
The probing task pipeline: Tokenizer -> Embedding -> MLP -> Classification.
Evaluation Highlights
- Merge rules alone allow models to predict character inclusion with 58.2% accuracy (vs 50% random guess) even when all linguistic meaning is stripped.
- Orthographic constraints (like 'q' implies 'u') contribute significantly: accuracy drops ~30 points when within-word constraints are removed.
- Semantic association is critical: replacing meaningful words with random strings drops character probing accuracy by ~11-13%.
Breakthrough Assessment
7/10
Provides the first systematic, causal explanation for a well-known phenomenon. While the models are small (nanoGPT), the experimental design is rigorous and offers fundamental insights into LM internal mechanics.