📝 Paper Summary
Memory recall
Context Compression
LongCodeOCR compresses long code contexts by rendering them into image sequences for Vision-Language Models, avoiding the semantic fragmentation caused by textual filtering while significantly reducing preprocessing time.
Core Problem
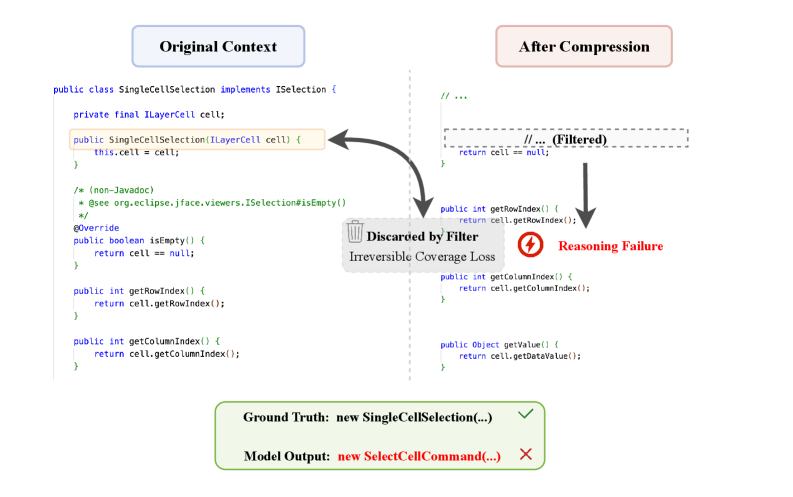
Existing textual code compression methods (like LongCodeZip) use selective filtering that often breaks dependency closure by removing prerequisites, leading to semantic fragmentation and reasoning failures in long contexts.
Why it matters:
- Code has strict dependency requirements; removing a definition while keeping its usage breaks syntactic validity and logic.
- Selective filtering incurs massive preprocessing overhead (e.g., ~4.3 hours for 1M tokens) due to numerous model forward passes for ranking.
- Current LLMs struggle with 'lost-in-the-middle' issues and quadratic complexity when processing ultra-long repository-scale contexts directly.
Concrete Example:
In a code completion task, a textual compressor might filter out the 'SingleCellSelection' class definition because it scores low on local perplexity. However, this definition contains the constructor signature required to instantiate the object later. Without it, the model hallucinates a non-existent class, causing runtime failure.
Key Novelty
Global-Preserving Visual Code Compression
- Replaces token-level pruning with visual rendering: converts code into 2D image sequences processed by Vision-Language Models (VLMs).
- Maintains a 'global view' of the codebase within a fixed visual token budget, preserving structural dependencies that textual filtering often destroys.
- Shifts the trade-off from 'coverage vs. compression' to 'coverage vs. fidelity,' retaining broader context at the cost of some symbol-level precision.
Architecture

Overview of the LongCodeOCR framework compared to Textual Code Compression. It shows the pipeline: Input Code -> Rendering -> Visual Encoder -> VLM.
Evaluation Highlights
- Improves CompScore on Long Module Summarization by 36.85 points over LongCodeZip at comparable compression ratios (~1.7x).
- Reduces compression-stage latency from ~4.3 hours (LongCodeZip) to ~1 minute (LongCodeOCR) at 1M token context length.
- Outperforms LongCodeZip in accuracy on the LongCodeQA benchmark (48.08% vs 46.50%) when using the specialized Glyph-9B VLM.
Breakthrough Assessment
8/10
Proposes a paradigm shift from textual filtering to visual processing for code memory. Drastically reduces latency and solves fragmentation, though fidelity issues remain for strict syntax tasks.