📝 Paper Summary
Modularized RAG pipeline
HARR optimizes the retriever component of RAG systems using reinforcement learning with a history-aware state representation to solve state aliasing in multi-hop reasoning.
Core Problem
Retrievers are typically optimized with proxy objectives (like supervised relevance) that misalign with the final answer quality, and standard RL is difficult due to deterministic retrieval and state ambiguity in multi-step reasoning.
Why it matters:
- Independent optimization of retrievers and LLMs creates an objective mismatch: relevant documents might not lead to correct answers.
- Scaling LLM fine-tuning is resource-intensive; optimizing the lighter retriever is more efficient but harder to align with end-to-end goals.
- In multi-hop QA, the same query can arise from different reasoning contexts, confusing the retriever if it ignores history.
Concrete Example:
In a multi-hop question, a query like 'Where was he born?' might appear twice. Without knowing the retrieval history (i.e., *who* 'he' refers to based on previous steps), the retriever cannot distinguish these states, leading to inconsistent rewards and failed learning.
Key Novelty
History-Aware Reinforced Retriever (HARR)
- Replaces deterministic Top-k retrieval with probabilistic sampling (Plackett-Luce model) to create a stochastic policy optimizable by RL.
- Augments the retriever's state with the full retrieval history (past queries and observations) to resolve ambiguity where identical queries imply different information needs.
- Optimizes the retriever directly on the final answer F1 score using Group Relative Policy Optimization (GRPO), aligning retrieval behavior with downstream performance.
Architecture
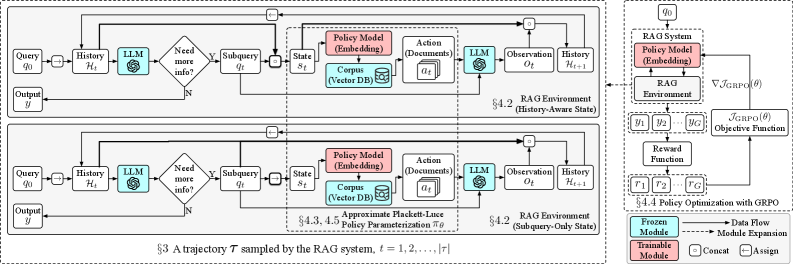
The MDP formulation of HARR, showing the interaction between the Retriever (Agent) and the LLM (Environment).
Evaluation Highlights
- Achieves consistent F1 improvements of +1.5 to +4.0 points over standard baselines on HotpotQA, 2WikiMultihopQA, and MuSiQue.
- Outperforms LLM-centric optimization methods (like Self-RAG) while freezing the LLM, demonstrating the efficacy of lightweight retriever tuning.
- Shows robust generalization across different retriever backbones (Contriever, BGE) and LLM sizes (7B, 13B).
Breakthrough Assessment
8/10
Effective application of RL to dense retrieval by addressing the specific challenges of discreteness and state aliasing. Strong empirical results with a lightweight approach.