📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Vision Transformer (ViT) Analysis
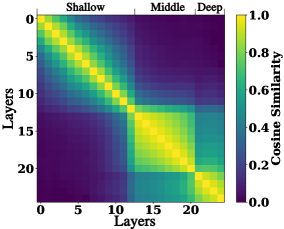
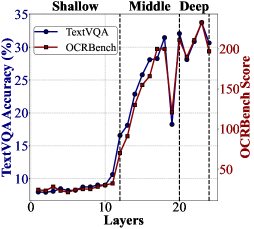
Systematic analysis reveals that shallow and middle ViT layers often outperform deep layers on fine-grained visual tasks, motivating a simple multi-layer fusion strategy that improves MLLM performance.
Core Problem
Most MLLMs use only the final or penultimate layer of the Vision Transformer (ViT) based on heuristics, ignoring potentially richer fine-grained visual information present in shallower layers.
Why it matters:
- Current deep-layer bias leads to suboptimal performance on tasks requiring fine-grained perception like counting and positioning.
- Scaling up the LLM size does not compensate for the loss of visual detail in the deep layers of the vision encoder.
- Existing fusion methods are often ad-hoc or heuristic rather than grounded in a systematic analysis of layer-wise efficacy.
Concrete Example:
In position-related tasks within the MME benchmark, using layer 18 (middle) outperforms the commonly used penultimate layer by 20%, showing that deep layers lose critical localization information.
Key Novelty
Layer-wise Visual Probing and Simple Fusion
- Systematically trains MLLMs connecting to every single ViT layer individually to empirically measure their downstream performance across diverse benchmarks.
- Identifies three distinct representation spaces (shallow, middle, deep) based on cosine similarity and performance patterns.
- Proposes a lightweight fusion method that linearly projects and sums features from one representative layer of each group (shallow, middle, deep) to capture both semantics and fine details.
Architecture
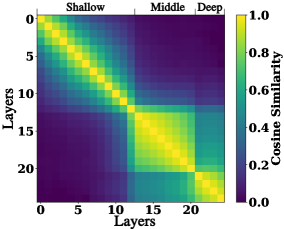
Illustration of the layer-wise representation groups and the fusion strategy.
Evaluation Highlights
- Layer 18 (middle) outperforms the penultimate layer by 20% on MME position tasks and 3% on CVBench using a 1.4B model.
- Proposed simple fusion method consistently outperforms single-layer baselines and complex fusion methods like DenseConnector and MMFuser across 10 benchmarks.
- On POPE (hallucination), half of the middle layers outperform the penultimate layer, suggesting reduced hallucination when using features that aren't over-optimized for text alignment.
Breakthrough Assessment
7/10
Provides the first comprehensive systematic analysis of layer-wise utility in MLLMs, challenging the standard practice of using only deep layers. The proposed solution is simple yet effective.