📝 Paper Summary
Theory of Mind (ToM)
Test-time compute / inference-time optimization
Sampling methods for LLMs
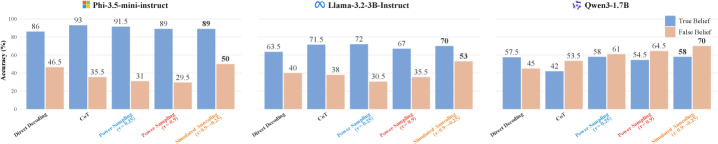
Applying simulated annealing to the sequence-level distribution of small language models recovers strong Theory of Mind capabilities, particularly for false belief tasks, without any parameter updates.
Core Problem
Autoregressive models optimize local plausibility (next-token prediction) rather than global coherence, causing them to fail at Theory of Mind tasks that require maintaining consistent latent belief states.
Why it matters:
- Models often contradict earlier commitments or implied states, failing to maintain a consistent 'world model'
- False Belief tasks are a critical test of reasoning, and failure implies a lack of robust social intelligence or planning capability
- Retraining or scaling up models is expensive; recovering capabilities from existing small models is more efficient
Concrete Example:
In a False Belief task where a character (Carlos) doesn't see a valve open, a standard model might correctly state the physical event but incorrectly infer Carlos knows it, or hallucinate that the valve was already open to justify his action. The proposed method correctly infers his ignorance and subsequent actions.
Key Novelty
Test-Time Simulated Annealing for Sequence Optimization
- Treats text generation as a global optimization problem over the sequence-level distribution rather than greedy next-token prediction
- Uses Markov Chain Monte Carlo (MCMC) with a cooling temperature schedule (annealing) to explore and then converge on globally coherent sequences
- Demonstrates that 'distorting' the probability landscape (sharpening) reveals latent reasoning abilities hidden by standard sampling
Architecture
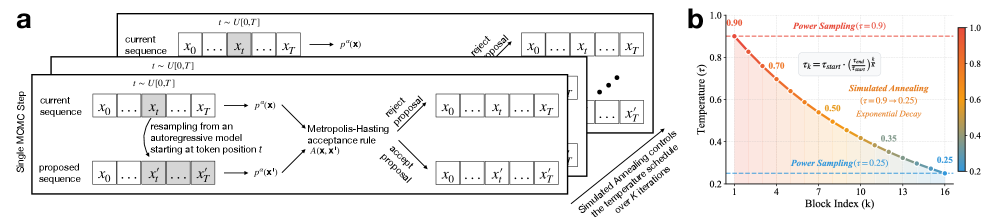
Comparison of Standard MCMC Power Sampling vs. Simulated Annealing MCMC
Evaluation Highlights
- Simulated annealing outperforms Chain-of-Thought and standard sampling on the BigToM benchmark, particularly on hard False Belief tasks
- Qualitatively recovers 'inverse planning' reasoning: models explicitly test hypotheses (e.g., 'If he believed X, he wouldn't do Y...')
- Small models (1.7B-3.8B parameters) achieve performance previously thought to require frontier-scale models
Breakthrough Assessment
7/10
Strong demonstration that 'reasoning failures' may be decoding failures. Unlocks significant capability in small models without training, though computational cost of MCMC is high.