📊 Experiments & Results
Evaluation Setup
Knowledge-based VQA with both Oracle and CLIP-based retrieval
Benchmarks:
- OK-VQA (Knowledge-based VQA)
- E-VQA (Encyclopedic VQA)
- InfoSeek (Fine-grained Entity VQA)
Metrics:
- Exact Match Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| MAD-RAG consistently outperforms vanilla RAG and baselines across all datasets using LLaVA-1.5-13B. | ||||
| OK-VQA | Accuracy | 60.46 | 65.22 | +4.76 |
| E-VQA | Accuracy | 58.40 | 67.60 | +9.20 |
| InfoSeek | Accuracy | 29.95 | 36.13 | +6.18 |
| OK-VQA | Accuracy | 61.35 | 65.22 | +3.87 |
| MAD-RAG specifically recovers performance on 'Attention Distraction' cases where Closed-Book was correct but RAG failed. | ||||
| OK-VQA | Recovery Rate (Quadrant: Closed=1, RAG=0) | 0.0 | 74.68 | +74.68 |
Experiment Figures

Attention heatmaps comparing Closed-book, Vanilla RAG, and MAD-RAG.
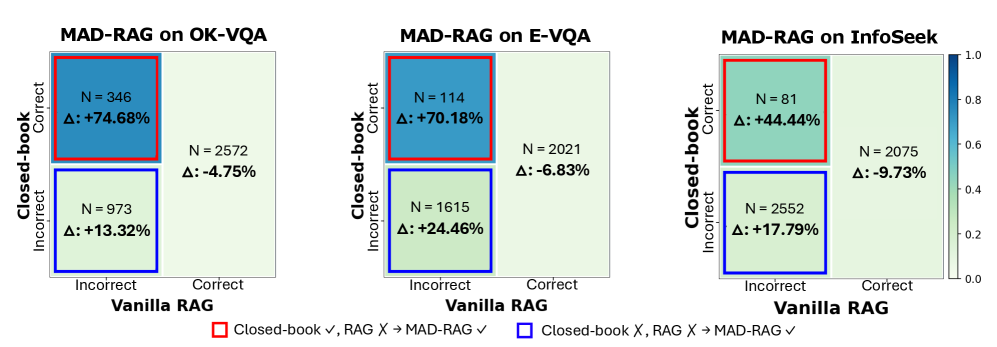
Performance breakdown by success/failure quadrants (Closed-book vs. RAG).
Main Takeaways
- MAD-RAG consistently outperforms existing baselines (CAD, ALFAR, etc.) across different model families (LLaVA, Qwen) and datasets.
- The method is robust to context length, maintaining gains even as retrieved context grows, unlike baselines that degrade.
- It effectively mitigates 'Attention Distraction' by recovering correct answers that were suppressed by retrieval, without sacrificing performance on cases where RAG was already helpful.