📝 Paper Summary
Graph-based RAG pipeline
MS-RAG improves RAG accuracy and speed by combining vector-based chunk retrieval with a multi-semantic knowledge graph index, using a novel mix recall algorithm instead of slow LLM-based entity extraction.
Core Problem
Existing graph-based RAG methods suffer from inefficient indexing (prone to LLM errors/hallucinations) and slow inference due to heavy reliance on LLMs for entity extraction during retrieval.
Why it matters:
- GraphRAG's reliance on LLM-based extraction is slow and costly, hindering industrial application
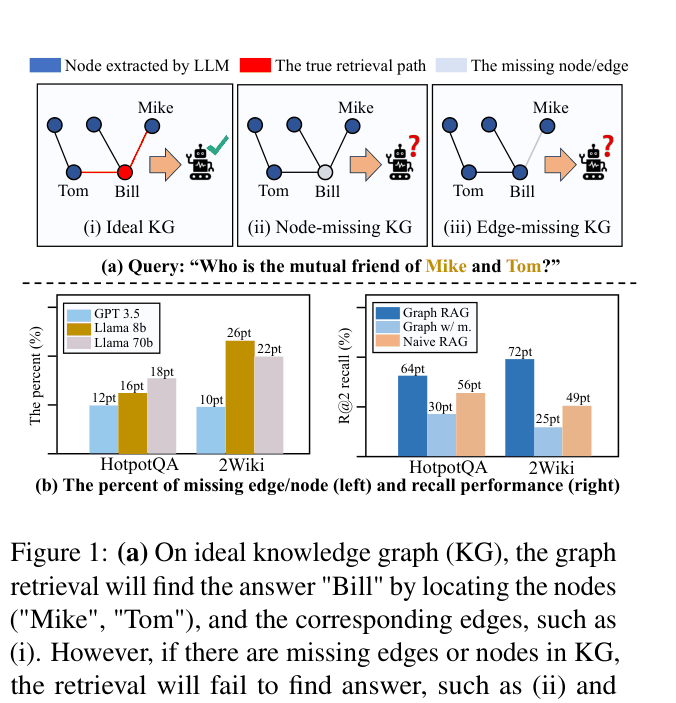
- Missing nodes or edges in LLM-constructed graphs cause retrieval failures worse than naive RAG (10-30% of samples in benchmarks have missing elements)
- Current methods fail to bridge the gap between structured graph reasoning and the speed/robustness of dense vector retrieval
Concrete Example:
In a question 'Who is the mutual friend of Mike and Tom?', if the LLM fails to extract the edge between 'Mike' and 'Bill' during indexing, standard graph retrieval fails completely. MS-RAG's inclusion of chunk-level vectors alongside graph nodes allows it to recover the answer even when specific graph edges are missing.
Key Novelty
Multi-Semantic Indexing with Mix Recall
- Create a unified index containing three levels of information: raw text chunks, extracted entities, and relations, all encoded as dense vectors
- Replace slow LLM-based entity extraction at inference time with fast vector search to identify relevant graph nodes
- Perform 'Mix Recall': retrieve relevant vectors (chunks) and graph neighbors (entities/relations) simultaneously, then fuse results via a voting-based reranker
Architecture
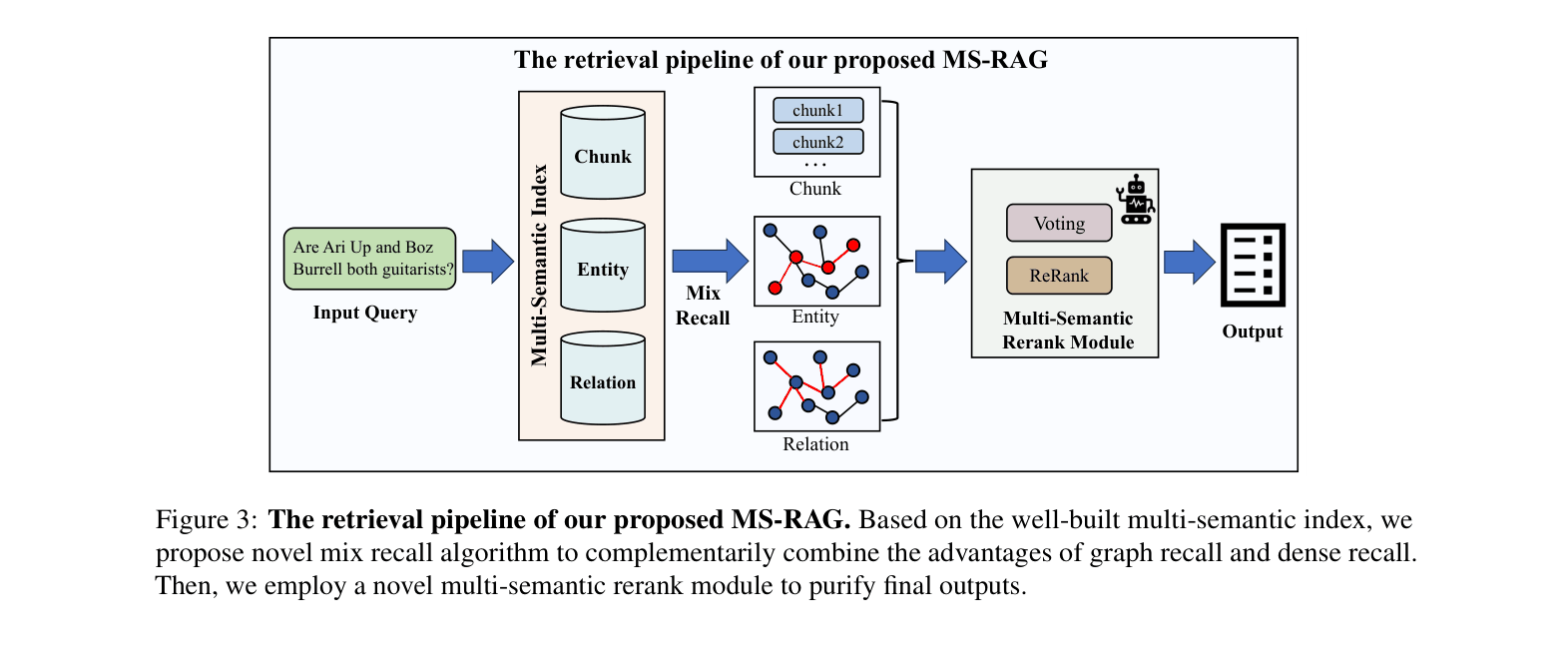
The retrieval pipeline of MS-RAG, detailing the Mix Recall and Multi-Semantic Rerank stages.
Evaluation Highlights
- Achieves state-of-the-art retrieval performance on HotpotQA, improving Recall@2 by +18.6% (77.6% vs 59.0%) over HippoRAG
- Inference speed is ~5x faster than GraphRAG (0.76s vs 4.12s) while achieving significantly higher correctness (72.3% vs 27.7%)
- Outperforms IRCoT+BM25 by +18.1% Recall@2 on average across three multi-hop datasets
Breakthrough Assessment
8/10
Significant improvements in both accuracy (SOTA retrieval) and efficiency (5x faster) by successfully hybridizing vector and graph approaches, addressing key industrial bottlenecks of GraphRAG.