📝 Paper Summary
Metacognition
Hallucination suppression
ESMA uses Evolution Strategies to align an LLM's explicit knowledge claims with its actual ability to answer correctly, optimizing a joint reward for accuracy and faithful self-assessment.
Core Problem
LLMs lack a reliable dependency between their internal knowledge and explicit reports; they may parrot memorized answers without knowing them, or claim knowledge/ignorance inconsistently with their actual performance.
Why it matters:
- Humans rely on a shared internal memory for both answering and reporting knowledge state, but this link is underexplored in LLMs
- Existing research focuses on utility (controlling refusal/hallucination) rather than the fundamental dependency between intrinsic knowledge and deployment
- Current alignment methods (SFT/RLHF) may encourage superficial pattern matching rather than genuine epistemic reporting
Concrete Example:
When asked 'Do you know X?', an LLM might answer 'Yes' and provide a wrong answer, or answer 'No' but actually be capable of answering correctly, showing a disconnect between its meta-assessment and its capabilities.
Key Novelty
Evolution Strategy for Metacognitive Alignment (ESMA)
- Utilizes a dual-prompt framework (Direct Question + Meta Question) to measure metacognitive sensitivity (d' type2)
- Applies Evolution Strategies (ES) instead of backpropagation to optimize a non-differentiable joint reward that requires coherence between two independent inference passes (answering and self-evaluating)
- Reinforces the binding between internal knowledge and output behavior, generalizing to new languages and prompt formats without explicit training on them
Architecture
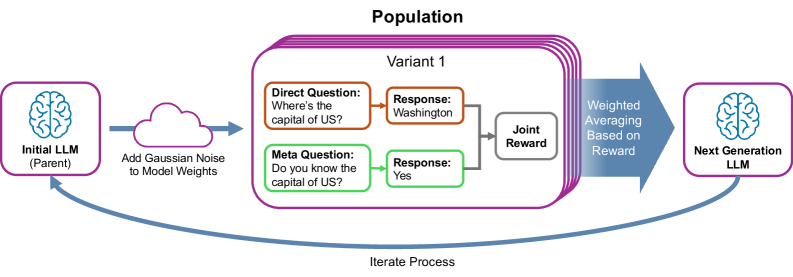
The ESMA optimization process using Evolution Strategies.
Evaluation Highlights
- Qwen2.5 3B with ESMA achieves d' type2 of 1.02, surpassing even closed-source models like GPT-5.2 and Claude Sonnet 4.5
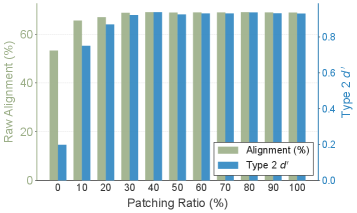
- Increases metacognitive alignment (d' type2) from 0.20 to 0.63 using only the top 10% of high-magnitude parameter updates
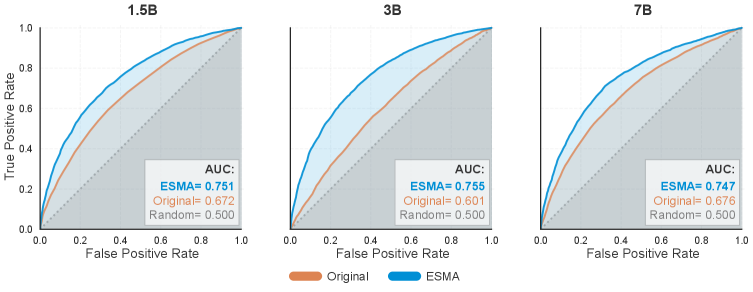
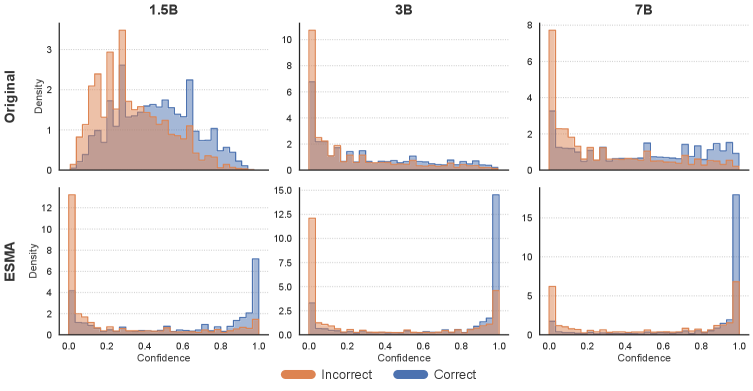
- Achieves AUC ~0.75 in continuous confidence analysis after fine-tuning, reaching the high metacognition regime across all model scales
- Zero-shot generalization to 'I don't know' prompting yields significant alignment gains (e.g., 59.88% to 78.07% for 3B model)
Breakthrough Assessment
8/10
Significant methodology for fundamental epistemic alignment. Demonstrates that ES can optimize holistic behavioral consistency where gradient methods fail, with strong generalization across unobserved settings.