📝 Paper Summary
Hallucination mitigation
Continual pre-training
PretrainRL mitigates factual hallucinations by identifying high-probability falsehoods during the pre-training phase and down-weighting them using Direct Preference Optimization (DPO), thereby making room for learning low-probability truths.
Core Problem
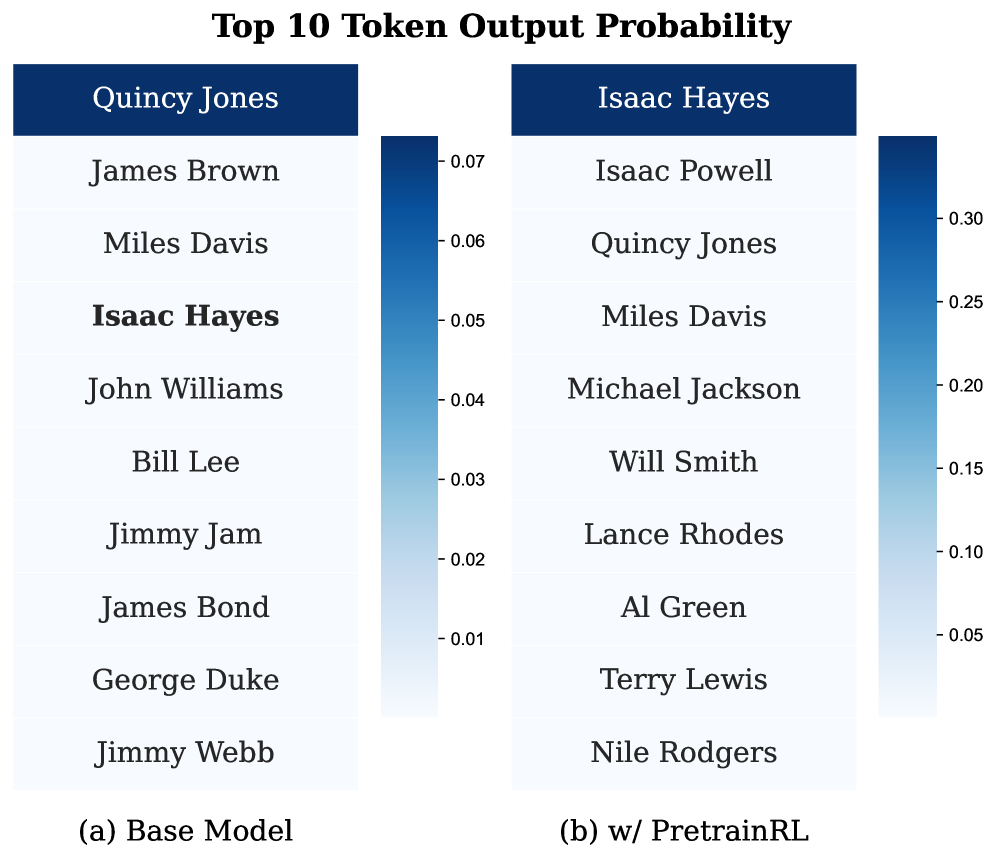
Pre-training data often has imbalanced distributions where frequent 'head' knowledge dominates, causing models to learn marginal probabilities (e.g., 'shoes are red') rather than conditional truths, leading to 'high-probability falsehoods' that block the learning of 'tail' facts.
Why it matters:
- Standard Next-Token Prediction (NTP) forces models to fit these biased distributions, embedding hallucinations deeply before fine-tuning even begins
- Post-hoc fixes like 'I don't know' alignment or knowledge editing often cause catastrophic forgetting or merely mask the underlying issue rather than fixing the probability distribution root cause
Concrete Example:
If a corpus mentions 'Brand A shoes are red' 1000x more often than 'Brand B shoes are blue', the model learns a shortcut associating 'shoes' with 'red'. When asked about Brand B, it hallucinates 'red' because the high-probability head knowledge (red) squeezes out the low-probability tail truth (blue).
Key Novelty
Debiasing Then Learning via Pre-training DPO
- Applying Direct Preference Optimization (DPO) during the continual pre-training phase to actively reshape the probability distribution
- Uses a 'debiasing' strategy: first lowers the probability of popular but incorrect answers (falsehoods) to 'make room' in the model's capacity, then boosts the probability of the correct tail knowledge
- Introduces an efficient beam-search-based negative sampling method to automatically discover these 'high-probability falsehoods' without needing access to the original training corpus statistics
Architecture
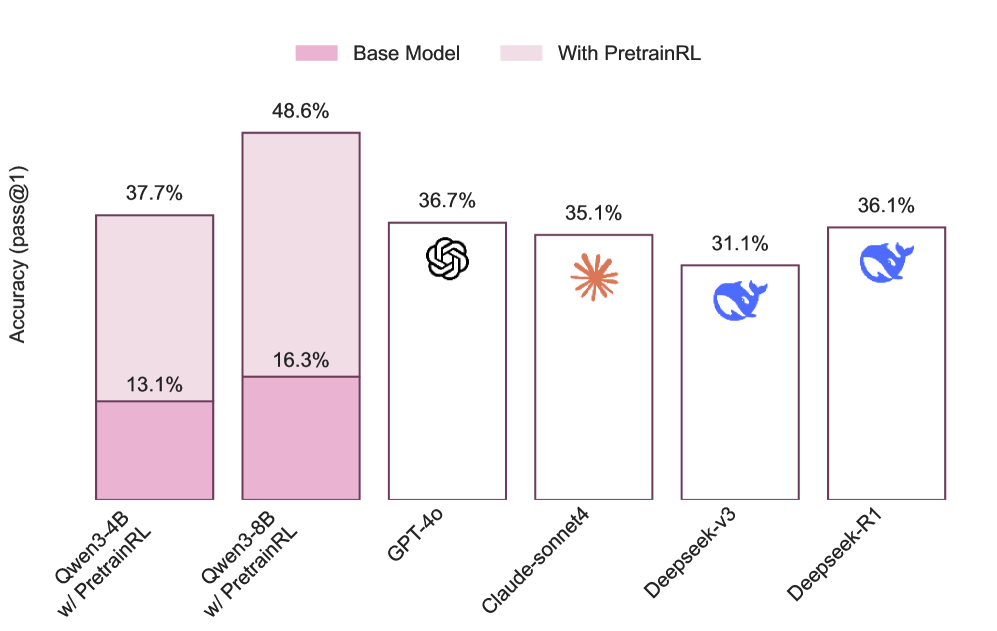
Comparison of PretrainRL vs. standard methods and the core workflow. (Note: Paper does not have a dedicated architectural block diagram, but Figure 1 conceptualizes the performance gap and Section 3 describes the flow).
Evaluation Highlights
- +15.6% Accuracy improvement on POPQA using Qwen3-4B-Base compared to standard Continued Training (CT)
- +13.3% Accuracy improvement on Wikidata-Knowledge Infusion benchmark with Llama3-8B-Base compared to base model
- Achieves superior performance on long-tail knowledge datasets without degrading general capabilities on benchmarks like MMLU and GSM8K
Breakthrough Assessment
8/10
Addresses the root cause of hallucination (data imbalance) during pre-training rather than post-hoc. The shift from post-training RL to pre-training RL for knowledge consolidation is methodologically significant.