📝 Paper Summary
Sparse Large Language Models
Model Scaling Laws
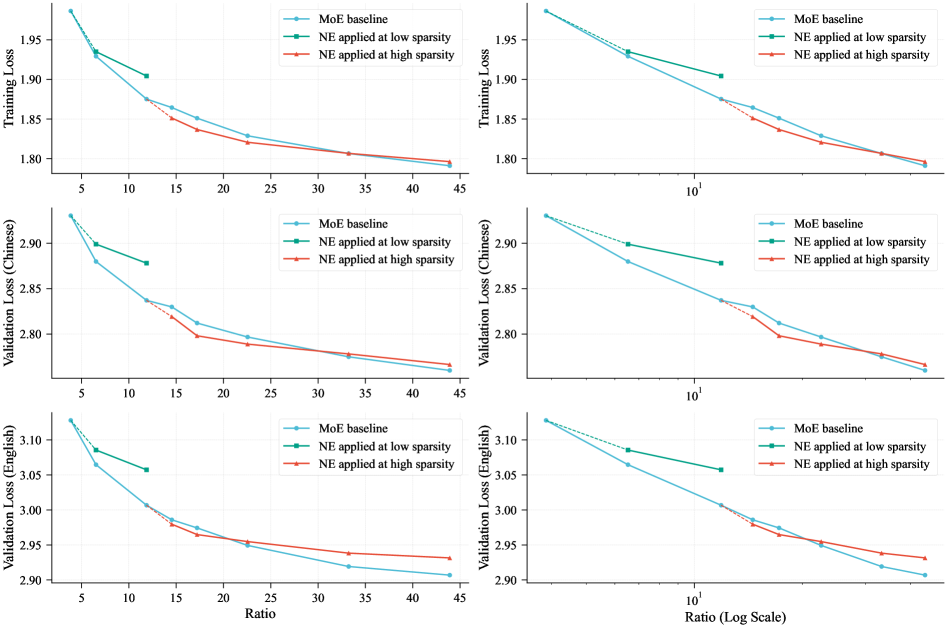
LongCat-Flash-Lite demonstrates that scaling embedding parameters via N-gram lookup tables is a superior alternative to scaling Mixture-of-Experts (MoE) parameters for high-sparsity, wide architectures, enabling massive parameter counts without computational explosion.
Core Problem
Mixture-of-Experts (MoE) architectures face diminishing returns and system-level bottlenecks (communication overhead, memory bandwidth) as expert counts increase, eventually hitting an efficiency saturation point.
Why it matters:
- Continued scaling of LLMs to trillions of parameters requires maintaining modest inference latency, which standard MoE scaling struggles to sustain due to routing overheads.
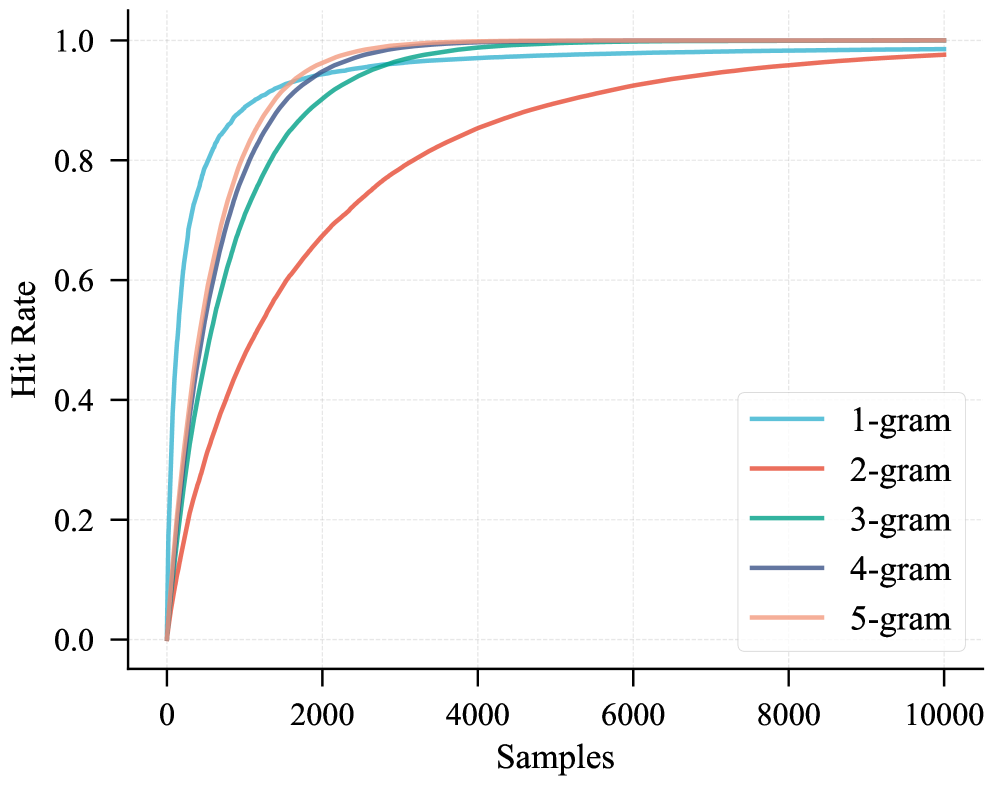
- Existing methods overlook the embedding layer as a sparse scaling dimension, despite its O(1) lookup complexity and potential for parameter expansion without computation explosion.
Concrete Example:
In a standard MoE model, adding more experts increases communication costs during distributed training. The paper shows that at high sparsity ratios (e.g., >20 total-to-active parameters), simply adding more experts yields diminishing loss reductions compared to allocating those parameters to N-gram embeddings.
Key Novelty
Embedding Scaling as an Orthogonal Dimension to MoE
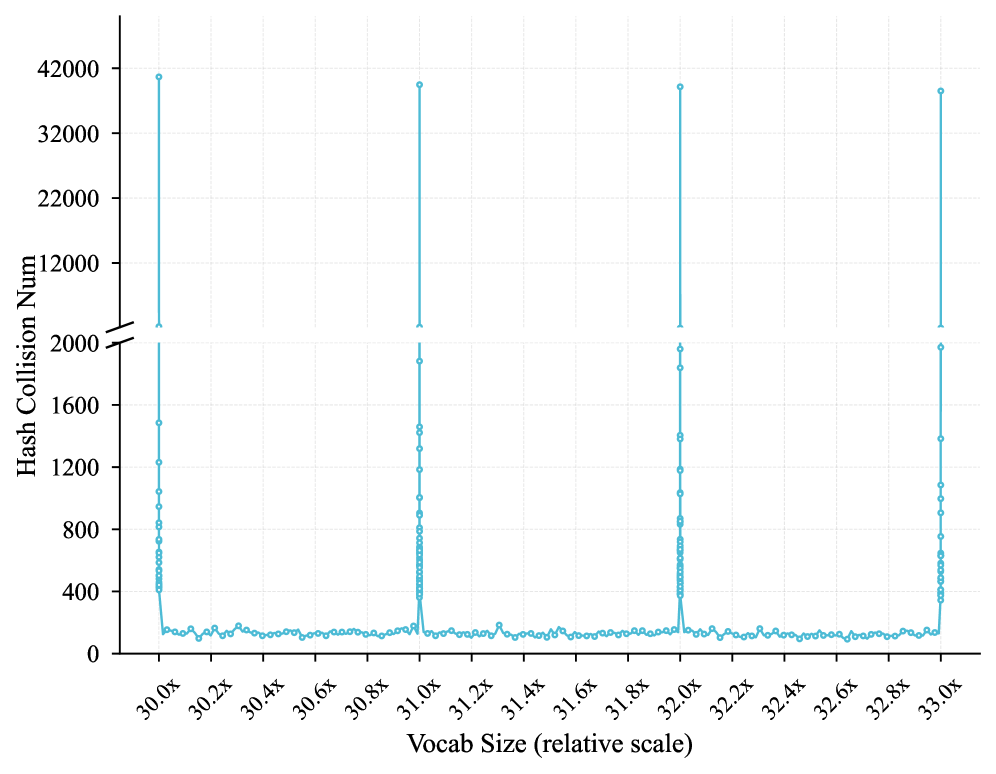
- Allocates a massive portion of the parameter budget (>30B) to N-gram embeddings rather than Feed-Forward Network experts, utilizing a hash-based lookup that densifies information per token.
- Identifies specific regimes (high sparsity, wide models) where embedding scaling achieves a better Pareto frontier than expert scaling.
- Introduces 'Embedding Amplification' (scaling factors or LayerNorm) to prevent the massive embedding signal from being drowned out by attention outputs in deep networks.
Architecture
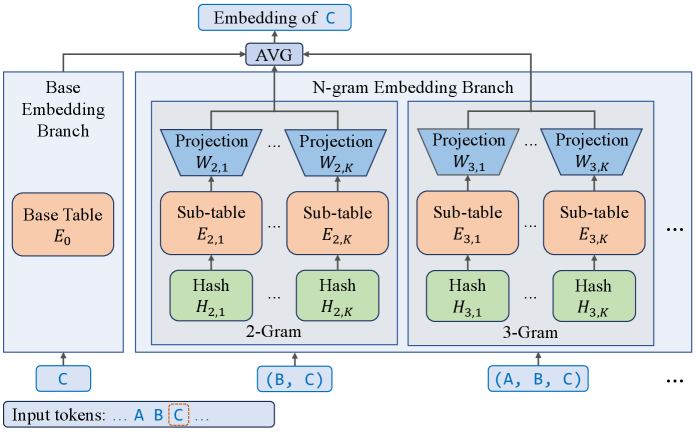
The structure of the N-gram Embedding layer.
Evaluation Highlights
- LongCat-Flash-Lite (68.5B total params, ~3B activated) surpasses a parameter-equivalent MoE baseline on both training and validation losses.
- Embedding scaling consistently outperforms expert scaling in wide models (1.3B activation size) even at sparsity ratios as high as 50:1.
- Application of Embedding Amplification reduces training and validation loss by 0.02 consistently compared to vanilla initialization.
Breakthrough Assessment
8/10
Offers a distinct, validated alternative to the dominant MoE scaling paradigm. By proving embedding scaling is more efficient for wide, high-sparsity models, it opens a new avenue for efficient LLM design.