📝 Paper Summary
Language Model Pretraining
Synthetic Data for LLMs
Pretraining language models on small amounts of abstract, algorithmically generated data (like formal languages) significantly improves performance and data efficiency on downstream tasks like coding and math.
Core Problem
LLMs simultaneously learn facts and reasoning skills from the same data, leading to entangled representations where models rely on surface-level heuristics rather than systematic reasoning.
Why it matters:
- Current models struggle to generalize because they memorize semantic shortcuts instead of learning robust algorithmic procedures.
- Standard pretraining is data-hungry; finding ways to 'warm up' models with cheaper, synthetic data could drastically reduce training costs.
Concrete Example:
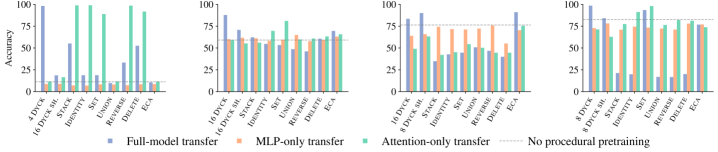
A model trained only on natural language might struggle with 'Needle-in-a-haystack' retrieval because it relies on semantic associations rather than position-aware processing. The paper shows pretraining on balanced brackets (Dyck sequences) jumps accuracy from 10% to 98%.
Key Novelty
Procedural Pretraining as Algorithmic Scaffolding
- Expose models to abstract, structured data (e.g., sorting numbers, formal languages) *before* standard semantic pretraining.
- This 'warms up' specific neural mechanisms: attention layers learn structure (useful for code), while MLPs learn pattern matching (useful for language), without requiring expensive semantic data.
Architecture
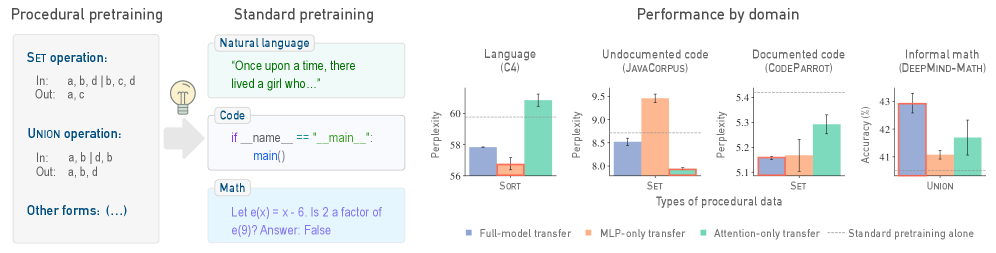
Illustration of the 'entangled' learning problem in standard LLMs vs. the 'disentangled' approach of procedural pretraining.
Evaluation Highlights
- On context recall (Needle-in-a-haystack), procedural pretraining improves accuracy from 10% to 98%.
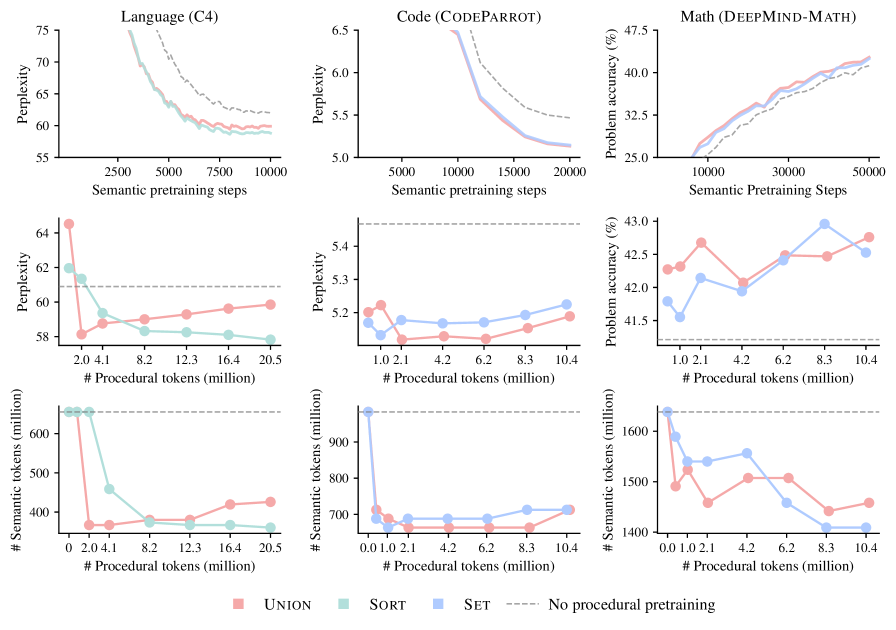
- Procedural pretraining enables models to reach baseline loss on C4 (natural language) using only 55% of the original semantic data.
- Adding just 0.1% procedural data consistently outperforms standard pretraining baselines on CodeParrot and DeepMind-Math.
Breakthrough Assessment
8/10
Strong empirical evidence that cheap synthetic data can replace large chunks of expensive real data. The finding that different layers (Attention vs MLP) benefit from different data types is theoretically significant.