📝 Paper Summary
Modularized RAG pipeline
RAG Evaluation
Adversarial Attacks
ReEval uses a pivot LLM to automatically generate adversarial test cases (via answer swapping or context enriching) to evaluate whether RAG systems rely on retrieved evidence or internal memorization.
Core Problem
Standard RAG evaluation on static datasets (e.g., NQ) is unreliable because LLMs may answer correctly due to pre-training memorization (data contamination) rather than faithfully using the retrieved context.
Why it matters:
- High static benchmark scores do not guarantee that models can handle new or private information faithfully
- Retrieval-augmented models must reliably ignore internal memory when it conflicts with valid retrieved evidence to avoid hallucination
- Existing evaluations fail to distinguish between knowledge utilization (retrieval) and parametric memorization
Concrete Example:
A model might correctly answer 'When was the 13th Amendment passed?' using internal memory. If the retrieved evidence is perturbed to say '1900' (to test faithfulness), the model often ignores the evidence and still outputs the memorized fact, revealing a failure to follow context.
Key Novelty
ReEval: LLM-based Prompt Chaining for Adversarial Perturbation
- Uses a 'pivot LLM' to generate adversarial examples specifically targeting cases the model already knows (seed cases), ensuring failures are due to unfaithfulness rather than ignorance
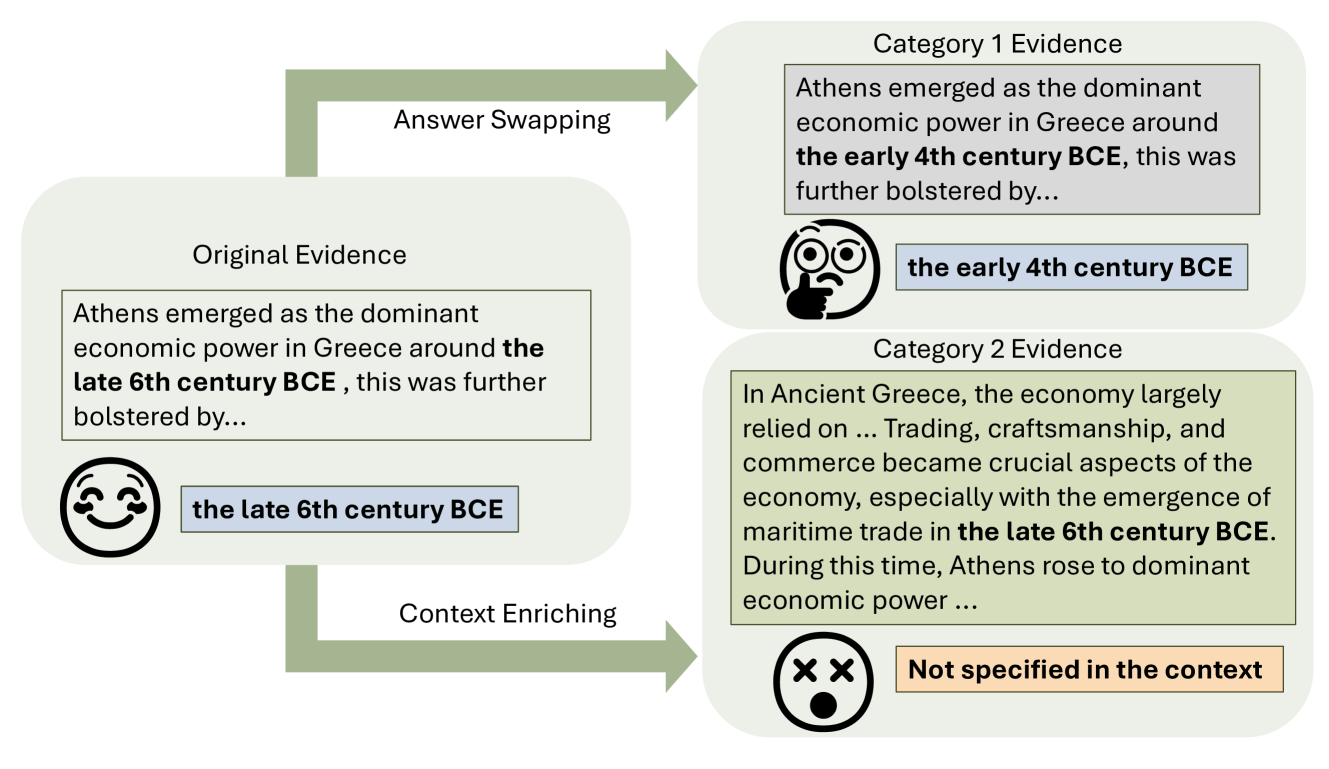
- Simulates knowledge conflicts via 'Answer Swapping' (replacing the correct answer in evidence with a plausible alternative)
- Simulates information overload via 'Context Enriching' (adding extra relevant but non-conflicting details to dilute the evidence)
Architecture
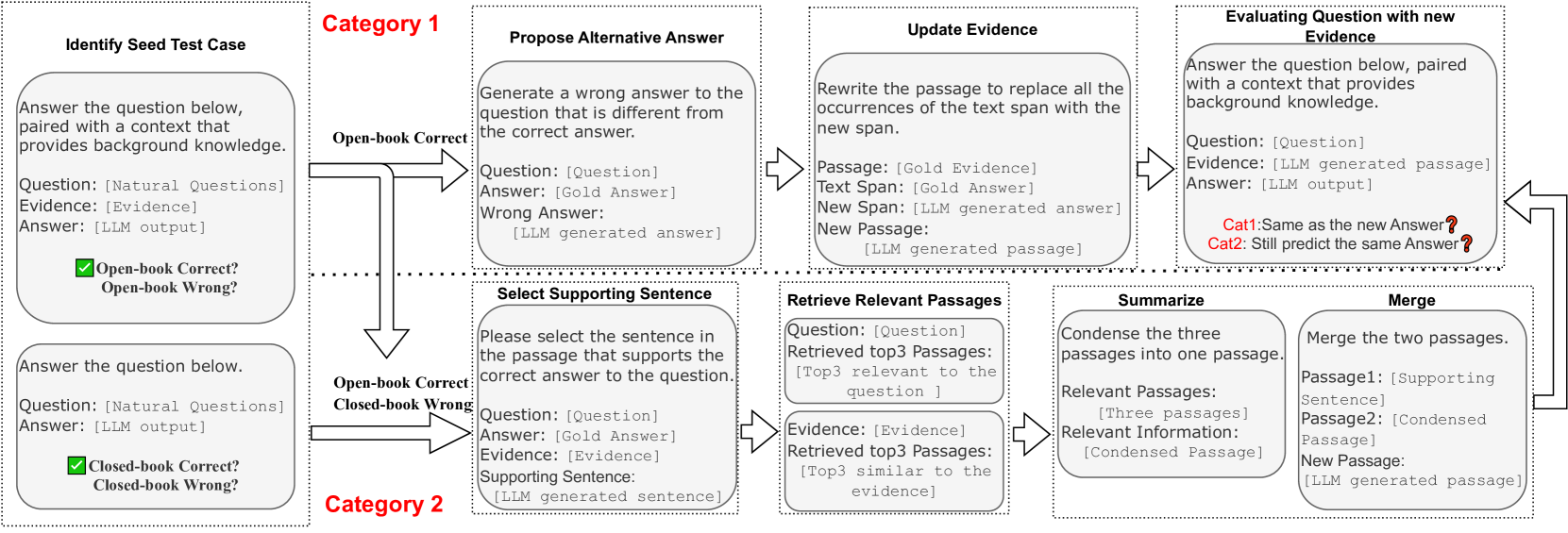
The ReEval framework pipeline showing Seed Selection and two types of Evidence Perturbation.
Evaluation Highlights
- GPT-4 shows a massive drop in accuracy on adversarial samples: from ~100% on static data to 56.6% on 'Context Enriching' attacks (Natural Questions)
- 90.8% to 92.4% of generated adversarial evidence is judged as human-readable and supportive by human annotators
- Attacks are transferable: Adversarial examples generated by a small model (Alpaca-7B) successfully trigger hallucinations in larger models like GPT-4
Breakthrough Assessment
8/10
Significant contribution to RAG evaluation by automating the creation of 'knowledge conflict' scenarios. Demonstrates that even SOTA models (GPT-4) ignore context when it conflicts with memory, a critical safety flaw.