📝 Paper Summary
Knowledge Editing
Conceptual Knowledge
Benchmarks
RelEdit is a benchmark for conceptual knowledge editing that evaluates not just if a concept definition changes, but whether related instances and hierarchical concept relationships update consistently.
Core Problem
Current knowledge editing evaluations focus on checking if a specific concept definition is updated but fail to assess whether the model correctly propagates these changes to related instances and conceptual hierarchies.
Why it matters:
- Changing an abstract concept (e.g., 'Gender') should logically alter the classification of specific instances (e.g., 'Non-binary') and relationships with other concepts (e.g., 'Psychology')
- Existing methods like ROME and MEMIT optimize for local factual updates and often fail to reason about the broader ontological consequences of a conceptual edit
Concrete Example:
If the concept 'Gender' is edited from a biological binary to a spectrum including psychological identity, the model should correctly classify 'Non-binary' as an instance of Gender and link Gender to Psychology. Current models might update the definition text but fail these relational checks.
Key Novelty
RelEdit Benchmark & MICE Baseline
- Introduces 5 novel metrics (Instance Change, Portability, Alignment Belong, etc.) to test if an edit propagates to instances and superclasses derived from DBpedia ontology
- Proposes MICE (Memory-based In-Context Editing), a retrieval-based method that stores edits in external memory and prompts the model to reason about contradictions, avoiding direct parameter updates
Architecture
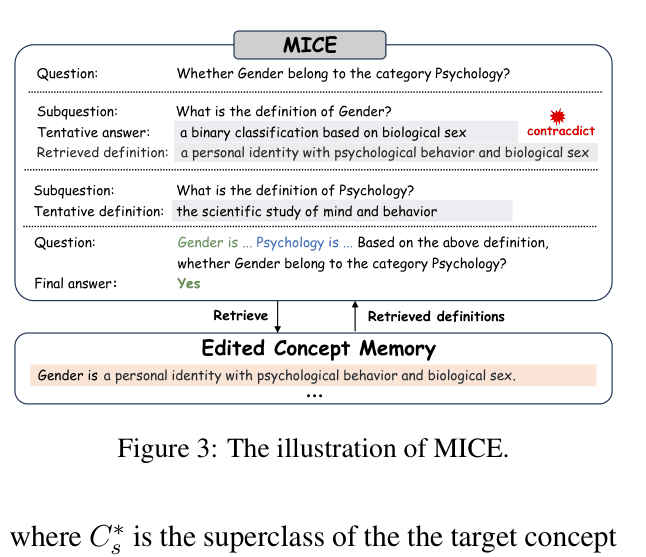
The workflow of MICE (Memory-based In-Context Editing)
Evaluation Highlights
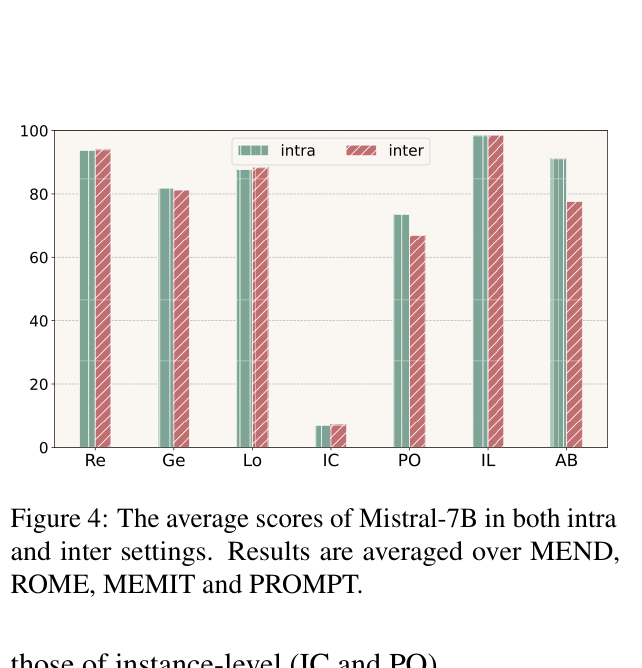
- Existing parametric methods (ROME, MEMIT) struggle with relational reasoning, scoring as low as 0.22-3.10 on Instance Change (IC) despite high reliability on direct definition recall
- MICE outperforms parametric editors significantly on relational metrics, achieving ~92-93% Reliability and strong instance-level consistency (Instance Change ~18%) compared to near-zero for baselines
- Larger models (e.g., Mistral-7B) generally handle relational reasoning challenges better than smaller models (e.g., GPT-2 XL) across all editing methods
Breakthrough Assessment
7/10
Identifies a critical gap in knowledge editing (conceptual ripple effects) and provides a rigorous benchmark. The proposed baseline (MICE) is simple but effective, though the low absolute scores on some metrics show the problem is far from solved.