📝 Paper Summary
Modularized RAG pipeline
FILCO improves retrieval-augmented generation by training a model to filter retrieved passages down to minimal supporting sentences using lexical and information-theoretic measures.
Core Problem
Imperfect retrieval systems often return irrelevant or distracting content, causing generation models to hallucinate or rely on spurious correlations even when correct answers are present.
Why it matters:
- Retrieval precision is often low (e.g., <5.0 unigram precision on NQ), overwhelming models with noise.
- Models over-utilize negative passages or get distracted by irrelevant sentences within positive passages.
- Feeding full retrieved passages increases computational cost and prompt length compared to filtering.
Concrete Example:
When asking 'When did the first train run in England?', a retriever finds a passage about the first railway in Belgium (1835) and England (1560s). Without filtering, the generator might be distracted by the 1835 date or other wagonway details. FILCO removes the irrelevant 1835 sentence, leaving only the 1560s sentence, helping the model answer correctly.
Key Novelty
Context Filtering via STRINC, LEXICAL, and CXMI measures (FILCO)
- Train a dedicated Context Filter model to identify and select only useful sentences from retrieved passages before they reach the generator.
- Create training data for the filter using three distinct oracle strategies: String Inclusion (exact match), Lexical Overlap (n-gram similarity), and Conditional Cross-Mutual Information (probability gain).
- Filter context at a fine-grained sentence level rather than the coarse passage level used in prior work.
Architecture
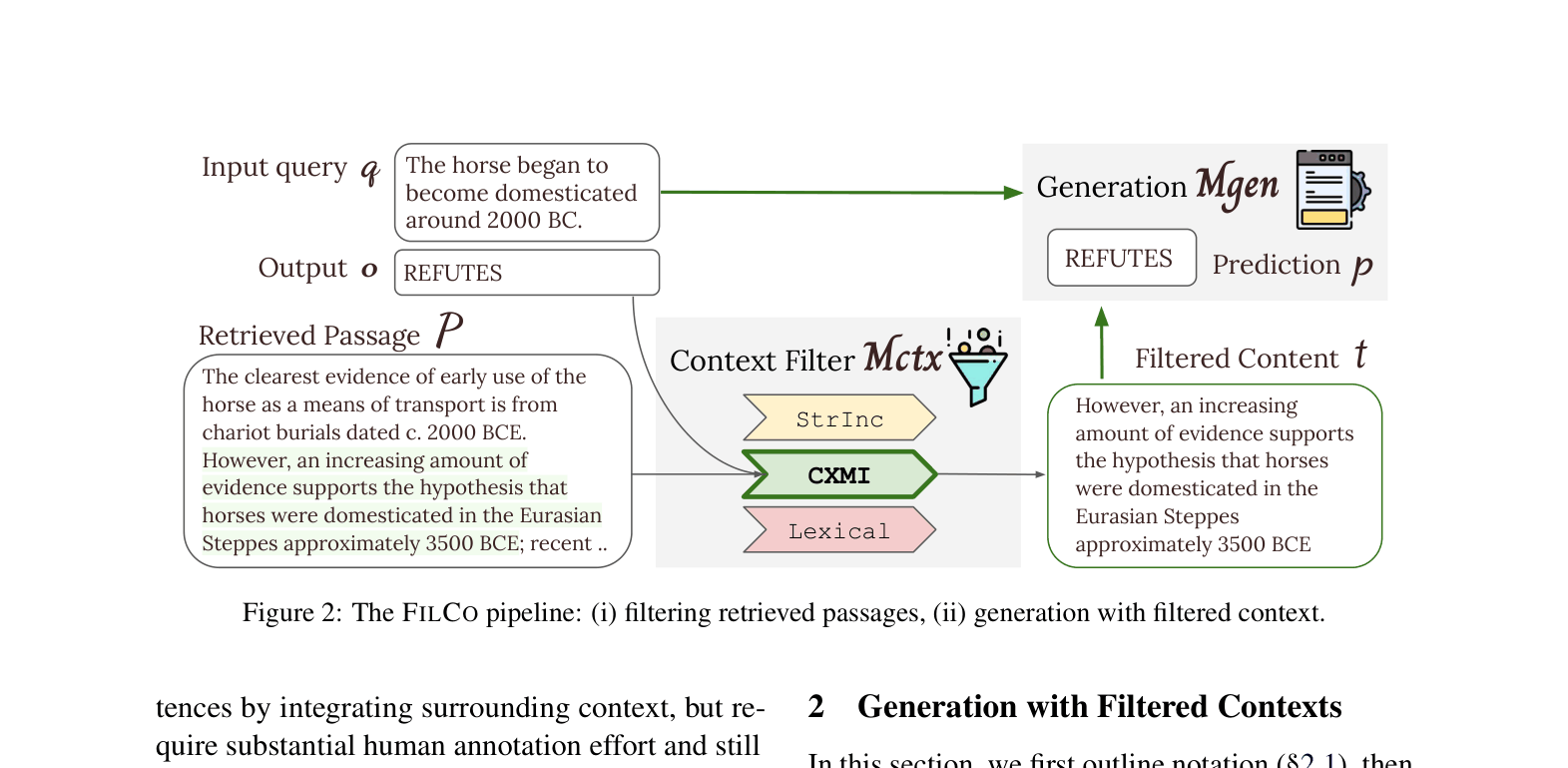
The FILCO pipeline demonstrating the two-step process: filtering context and then generating the answer.
Evaluation Highlights
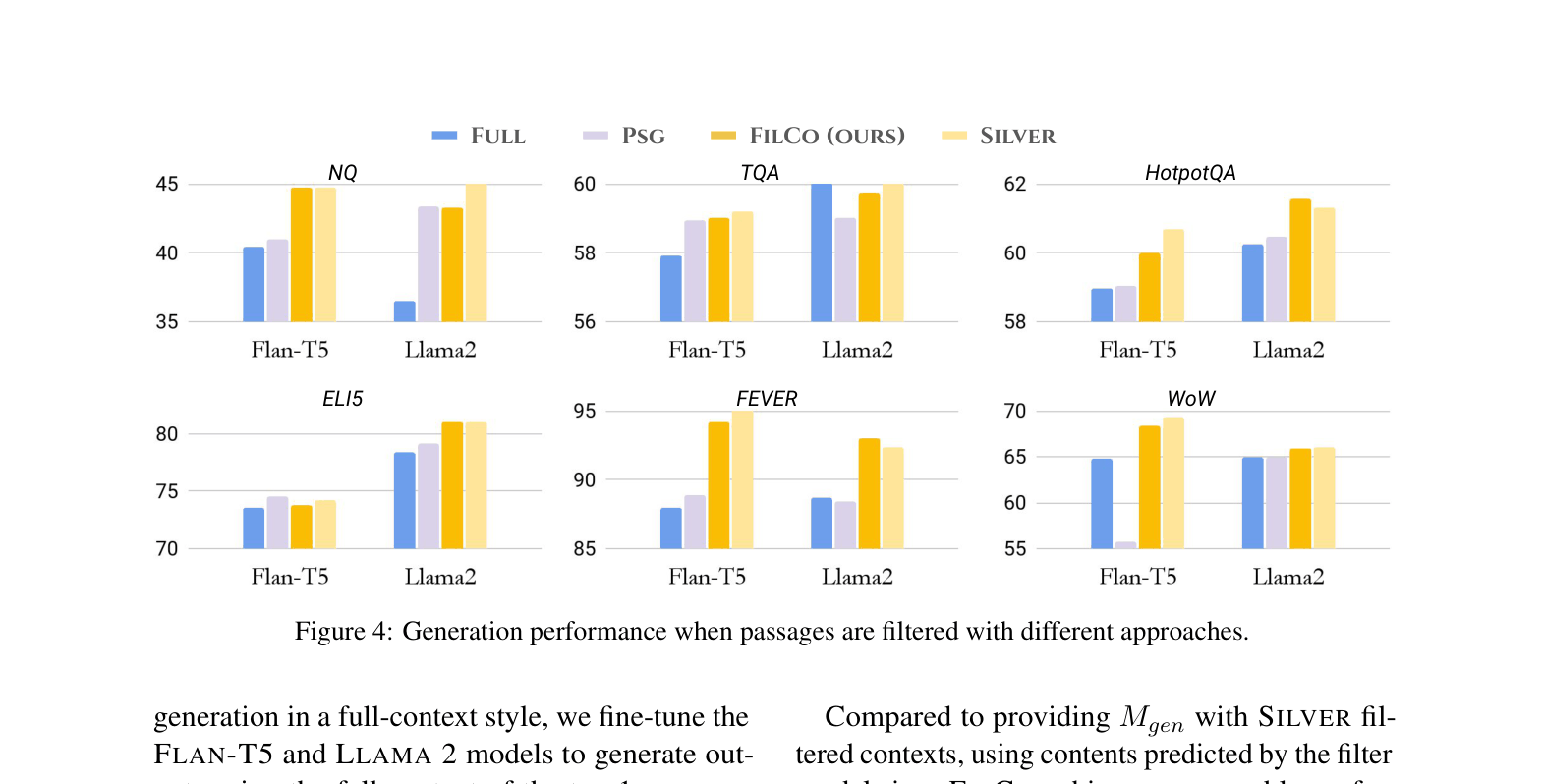
- +8.6 EM improvement on NaturalQuestions using Llama-2-7B compared to full-context baselines.
- +6.2 Accuracy improvement on FEVER (Fact Verification) using Flan-T5-XL by removing distracting non-evidential content.
- Reduces prompt length by 44-64% across tasks while maintaining or improving generation performance.
Breakthrough Assessment
7/10
Strong empirical results on filtering efficacy and token reduction. The comparison of three filtering strategies (StrInc vs. CXMI) provides valuable insights for different task types.