📝 Paper Summary
Efficient Multimodal LLMs
Visual Token Pruning
METEOR improves the efficiency of multi-encoder MLLMs by progressively pruning redundant visual tokens across encoding, fusion, and decoding stages using rank-based allocation and text-guided attention.
Core Problem
Multi-encoder MLLMs (like EAGLE) achieve high performance but suffer from prohibitive computational costs due to the quadratic scaling of visual tokens, especially with high-resolution inputs.
Why it matters:
- Processing high-resolution images with multiple encoders (e.g., 672x672 with dual encoders) generates thousands of tokens, causing extreme latency.
- Existing pruning methods designed for single encoders fail to handle the redundancy overlap between multiple encoders.
- Fixed pruning ratios perform poorly on fine-grained tasks like OCR, which require more visual details than general comprehension tasks.
Concrete Example:
In Mini-Gemini, a 672x672 image processed by dual vision encoders generates 2880 visual tokens. Standard pruning might aggressively cut tokens needed for OCR, or keep redundant background tokens shared by both encoders, failing to balance speed and accuracy.
Key Novelty
Progressive Multi-Stage Pruning for Multi-Encoder MLLMs
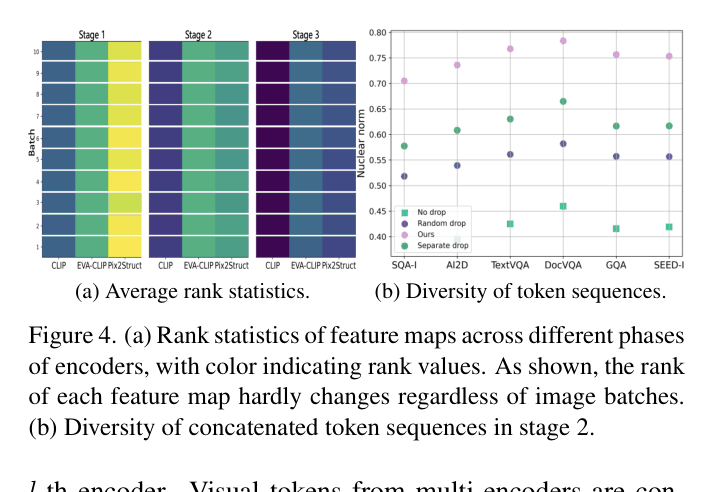
- Stage 1 (Encoding): Uses feature map rank to measure information richness, allocating fewer tokens to encoders with lower rank (less information).
- Stage 2 (Fusion): Introduces 'Post-projection Fusion' where each encoder has a dedicated projector, allowing the removal of mutually redundant tokens that overlap across encoders.
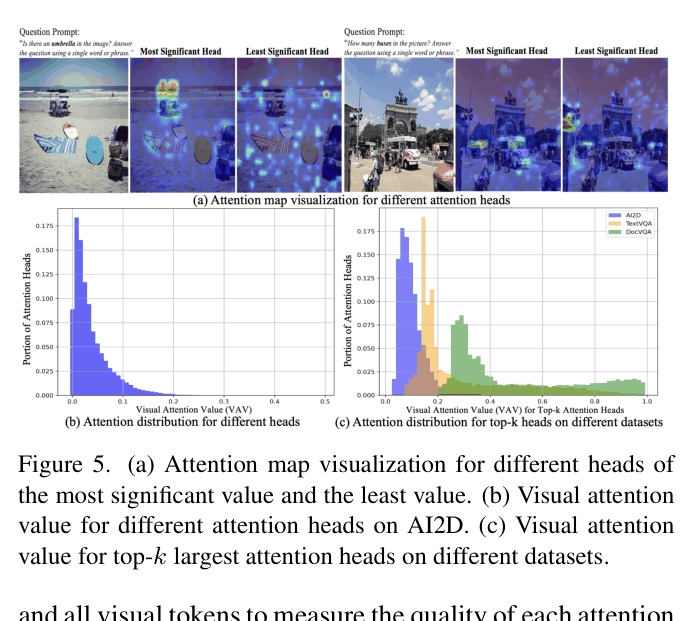
- Stage 3 (Decoding): Dynamically adjusts the number of retained tokens based on the 'Visual Attention Value' of the top-k most relevant attention heads, keeping more tokens for complex tasks like OCR.
Architecture
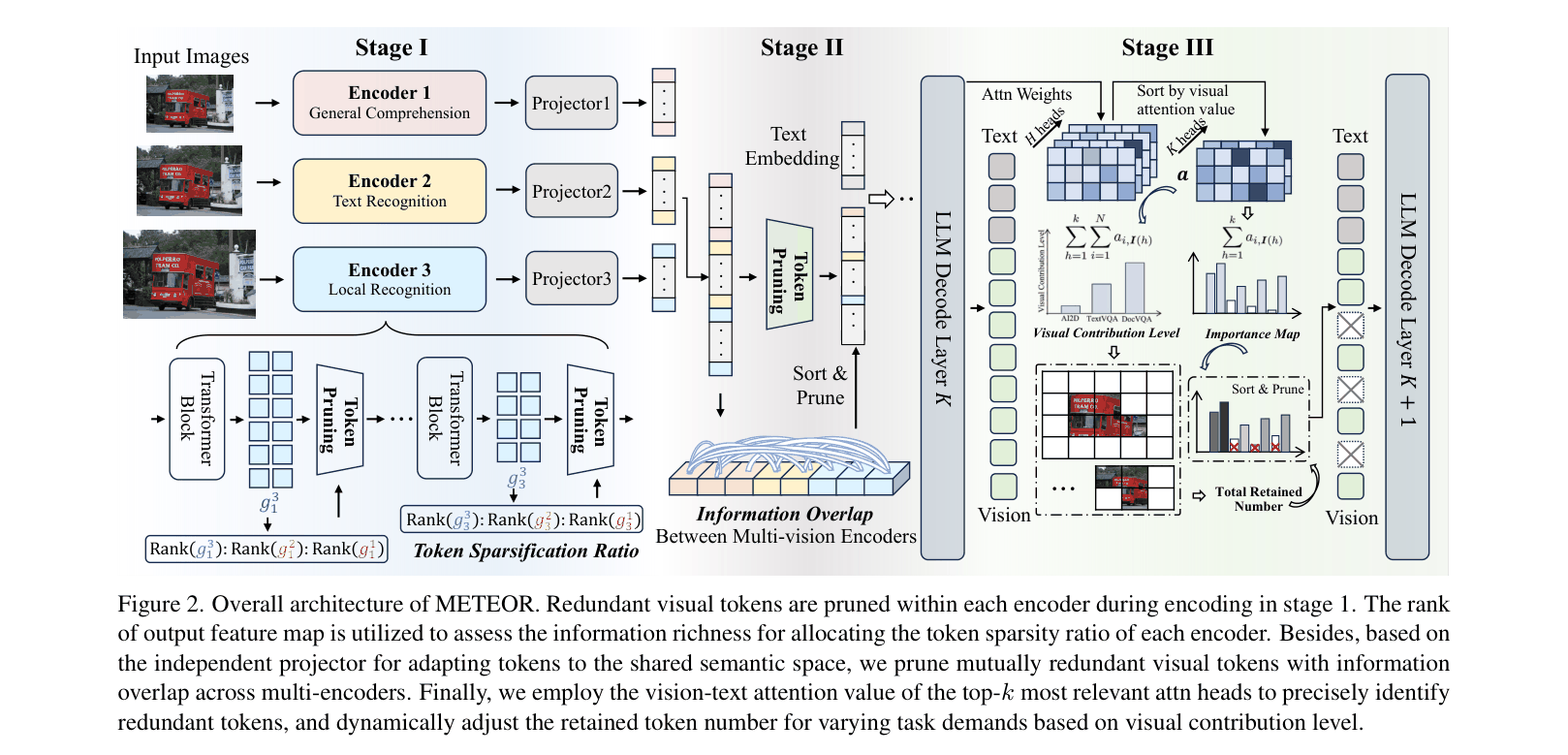
The 3-stage METEOR pipeline: (1) Encoding with rank-guided pruning, (2) Fusion with cross-encoder redundancy reduction, (3) Decoding with adaptive text-aware pruning.
Evaluation Highlights
- Reduces visual tokens by 76% compared to EAGLE while maintaining comparable performance (only 0.3% average drop across 11 benchmarks).
- Increases throughput by 46% and reduces TFLOPS by 49% compared to the EAGLE baseline.
- Outperforms state-of-the-art pruning method FastV by 4.1% on average, with significant gains (+12.3%) on OCRBench due to adaptive token retention.
Breakthrough Assessment
8/10
First framework specifically addressing token redundancy in multi-encoder MLLMs. The rank-based allocation and adaptive pruning strategy effectively solve the 'OCR vs. General' trade-off that plagues fixed-ratio pruning.