📊 Experiments & Results
Evaluation Setup
Perplexity evaluation on WikiText-103 and negative log-likelihood on synthetic Macondo dataset
Benchmarks:
- Macondo (Synthetic Generalization (Over-specification)) [New]
- WikiText-103 (Language Modeling)
Metrics:
- Perplexity (PPL)
- Negative Log-Likelihood (NLL)
- KL-divergence
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Bottleneck analysis shows the LM's last layer is expressive enough to match kNN-LM distributions, ruling out the softmax bottleneck hypothesis. | ||||
| WikiText-103 | Perplexity | 16.12 | 16.13 | +0.01 |
| Macondo experiments demonstrate the failure of vanilla LMs to generalize from over-specified data and the success of kNN/MLP augmentation. | ||||
| Macondo | NLL | 0.55 | 2.2 | +1.65 |
| Macondo | NLL | 2.2 | 0.6 | -1.6 |
| MLP Augmentation effectively reduces perplexity on standard benchmarks with minimal storage. | ||||
| WikiText-103 | Perplexity | 17.96 | 16.51 | -1.45 |
Experiment Figures
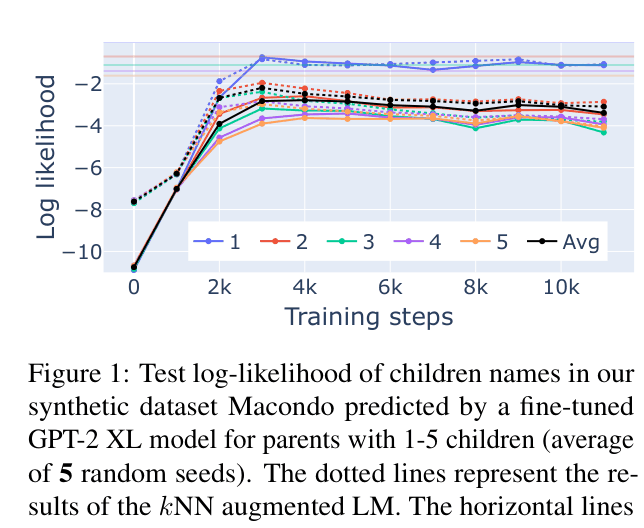
Negative Log Likelihood on Macondo test set for Vanilla, kNN, and MLP models vs. Theoretical Optimal
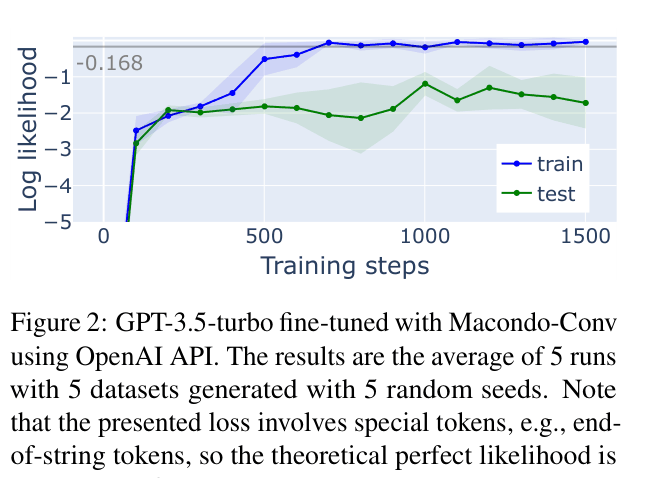
Performance of GPT-3.5 Turbo on Macondo-Conv (Conversational version)
Main Takeaways
- Softmax bottleneck is NOT the cause of the performance gap between vanilla and kNN-LMs; the last layer is sufficiently expressive.
- Vanilla LMs (even GPT-3.5) fail to generalize when training data is 'over-specified' (contains irrelevant details), whereas retrieval augmentation handles this robustly.
- An MLP trained to map context keys to values can replace the kNN datastore, reducing storage by 25x while retaining most perplexity gains.