📝 Paper Summary
Knowledge-Based Question Answering (KBQA)
Large Language Model Evaluation
This paper evaluates the GPT family's ability to replace traditional KBQA models using a comprehensive black-box testing framework covering ~190,000 complex questions across 8 datasets.
Core Problem
Existing evaluations of ChatGPT on Knowledge-Based Question Answering (KBQA) are limited in scale and scope, making it unclear if LLMs can replace traditional models that query structured knowledge bases.
Why it matters:
- LLMs generate free-text answers rather than exact entities, making traditional Exact Match (EM) metrics unreliable without adaptation
- Current benchmarks lack large-scale testing of complex reasoning types (e.g., set operations, filtering) to identify specific LLM limitations
- It is unknown whether LLMs' internal knowledge can supersede the need for external structured Knowledge Bases (KBs) in complex QA
Concrete Example:
A traditional KBQA model queries a database for 'Person name'. ChatGPT generates a sentence like 'The person is [Name].' Standard evaluation fails to match this. Additionally, ChatGPT might answer correctly but fail when the same question is slightly paraphrased or has a typo.
Key Novelty
Feature-Driven Black-Box KBQA Evaluation Framework
- Treats LLMs as 'knowledge bases' and evaluates them using an extended Exact Match metric that parses constituent trees to find candidate answers
- Applies software engineering testing principles (CheckList) to KBQA: Minimal Functionality Tests (basic ability), Invariance Tests (robustness to typos/paraphrasing), and Directional Expectation Tests (controllability via prompts)
Architecture
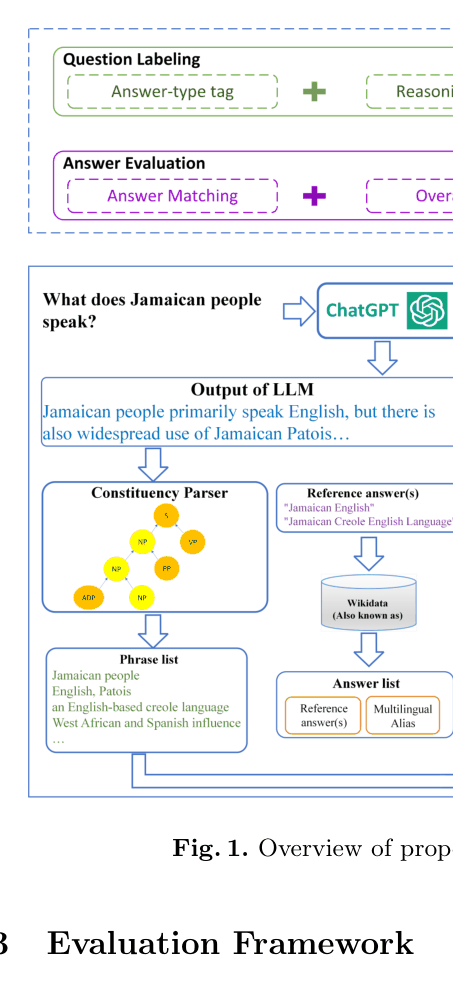
Overview of the Evaluation Framework
Evaluation Highlights
- GPT-4 achieves 90.45% accuracy on WebQuestionSP (WQSP), outperforming the state-of-the-art traditional model (73.10%)
- On the newer GrailQA dataset, GPT-4 (51.40%) still lags behind the traditional SOTA model (76.31%), showing LLMs struggle with the latest complex benchmarks
- GPT-4 demonstrates high stability (91.70%) in invariance tests, approaching the perfect stability (100%) of traditional models
Breakthrough Assessment
7/10
Comprehensive evaluation framework that adapts traditional QA metrics to LLMs. Provides valuable insights into the 'LLM as KB' hypothesis, though it doesn't propose a new model architecture.