📝 Paper Summary
Scaling Laws
Data Quality
Training Efficiency
Traditional scaling laws fail in high-density data regimes and over-training scenarios; a new sub-optimal scaling law incorporating data density and allocation ratios better predicts performance deceleration.
Core Problem
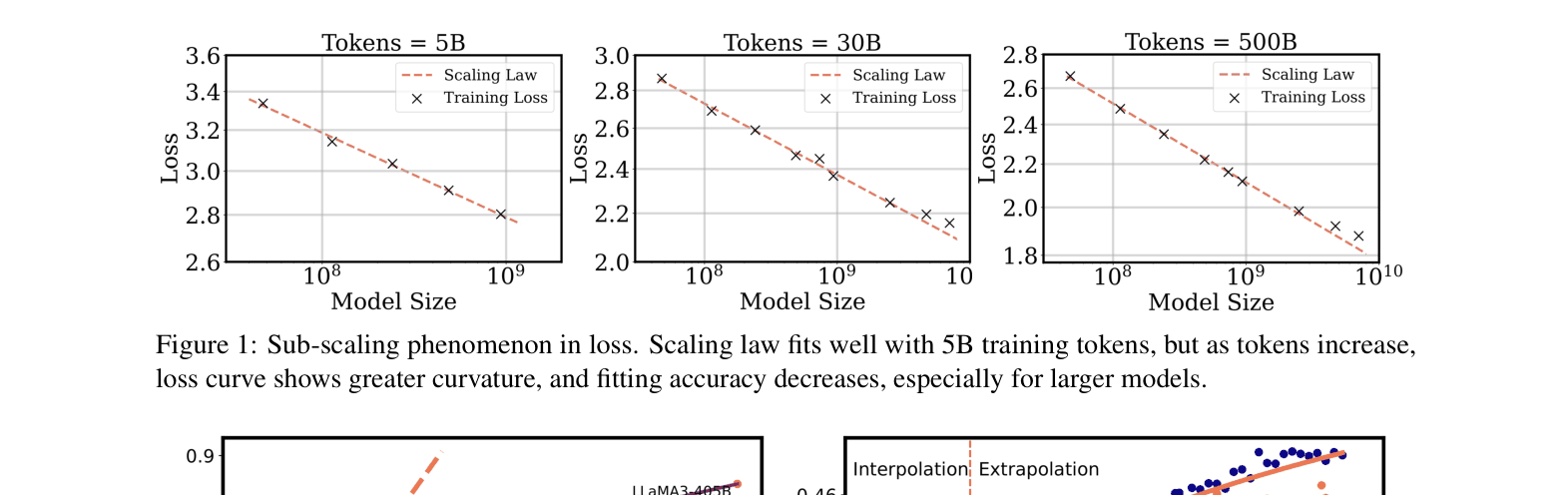
Traditional scaling laws predict power-law improvements, but recent large models exhibit 'sub-scaling' where performance gains decelerate significantly when trained on redundant data or with non-optimal compute allocation.
Why it matters:
- Blindly increasing model size or data volume yields diminishing returns, wasting massive computational resources.
- Current laws fail to account for data redundancy (density) and over-training (training small models on massive tokens), leading to inaccurate performance forecasts.
- Understanding these limits is crucial for efficient training of Large Language Models (LLMs) like LLaMA-3 which deviate from Chinchilla optimality.
Concrete Example:
When training LLaMA-3-8B on 15T tokens (massive over-training), performance gains slow down compared to LLaMA-2's trajectory despite better strategies. Traditional laws predict lower loss than actually observed because they ignore the redundancy in such vast datasets.
Key Novelty
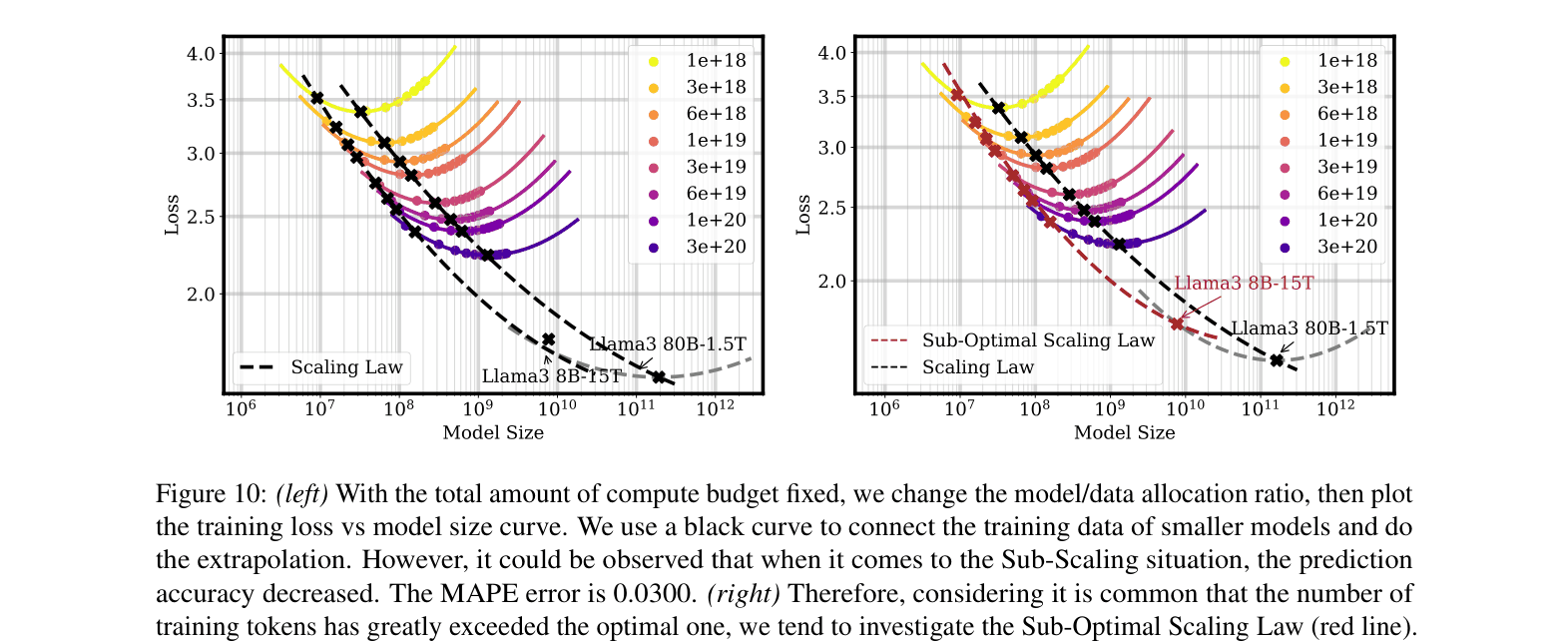
Sub-Optimal Scaling Law (SOSL)
- Introduces a 'density' metric that penalizes data redundancy: high-density clusters (repetitive concepts) contribute less information gain than diverse, low-density data.
- Generalizes the Chinchilla scaling law by adding decay factors based on data density and the Over-Training Ratio (OTR), mathematically modeling the diminishing returns observed in practice.
Architecture
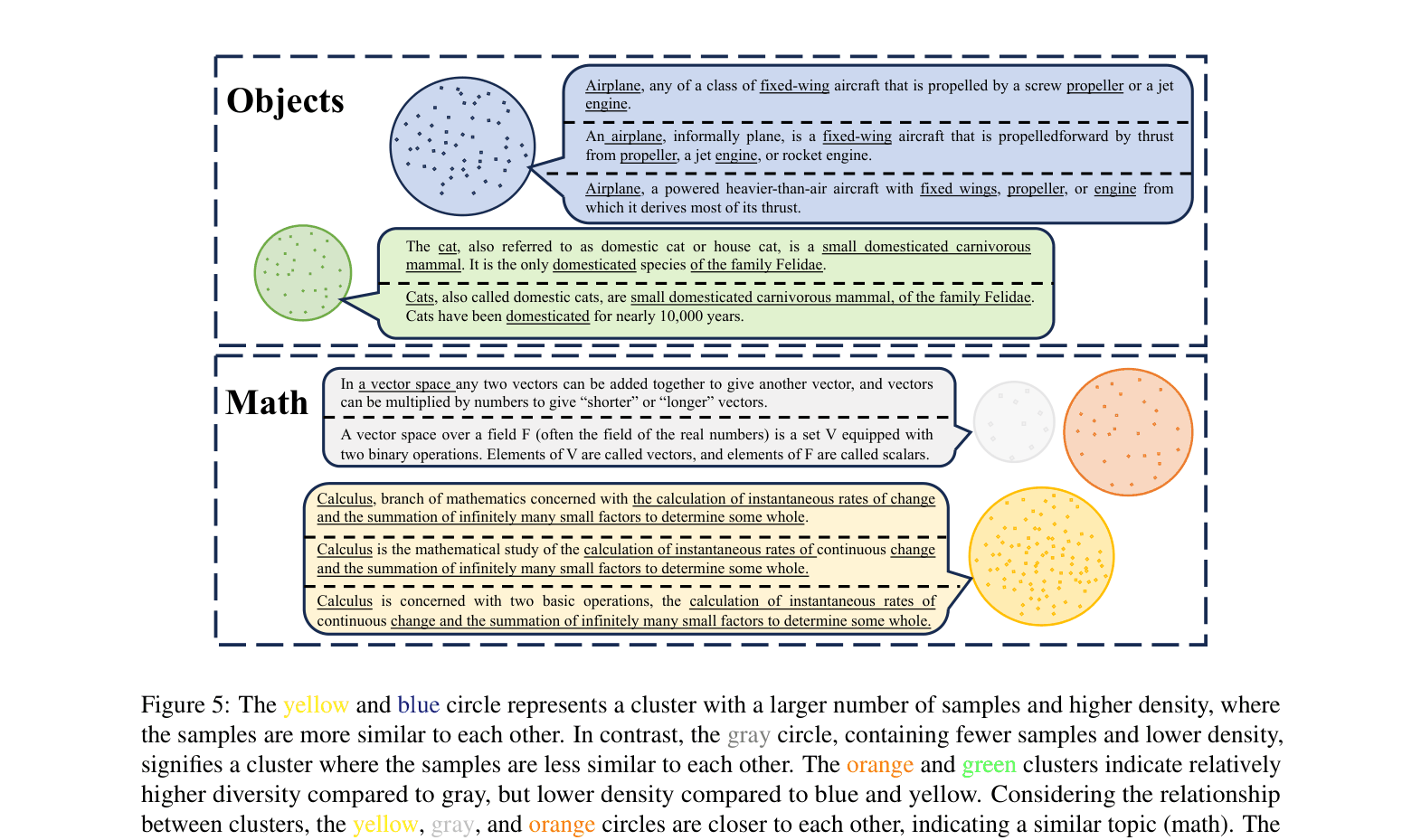
Conceptual visualization of data density. Figure 5 shows semantic clusters (circles) where high density = many similar samples (redundancy). Figure 6 plots sample count vs. cluster ID.
Evaluation Highlights
- Proposed Sub-Optimal Scaling Law reduces prediction error (MAPE) from 0.0245 (traditional law) to 0.0016 on 500B token training runs.
- Identifies a critical Over-Training Ratio (OTR) threshold of 50; beyond this point, increasing data volume yields stabilizing (diminishing) returns on loss reduction.
- Demonstrates that low-density data subsets (selected via the proposed metric) sustain linear-like performance growth longer than high-density raw data.
Breakthrough Assessment
8/10
Provides a mathematically grounded correction to widely used scaling laws, specifically addressing the modern regime of 'over-training' small models on massive data.