📝 Paper Summary
LLM-based Evaluation
Automatic Critique Generation
CritiqueLLM is a critique generation model trained on data synthesized via a multi-path prompting strategy that transfers insights from referenced pointwise critiques to reference-free and pairwise settings.
Core Problem
Existing LLM-based evaluators often generate generic, uninformative critiques, especially in reference-free settings where they lack fine-grained distinguishability.
Why it matters:
- LLM evaluations (LLM-as-a-judge) are becoming standard, but relying solely on API-based models like GPT-4 is costly and poses data leakage risks
- Reference-free evaluation is critical for open-ended tasks where ground truth is unavailable, yet current open-source models struggle to be specific without references
- Uninformative critiques fail to provide actionable feedback for improving model generation quality
Concrete Example:
When evaluating a generated summary without a reference, a standard model might say 'The summary is good but could be more detailed,' whereas CritiqueLLM identifies specific missing entities or hallucinations by leveraging training data derived from reference-aware teacher outputs.
Key Novelty
Eval-Instruct (Multi-Path Prompting for Data Construction)
- Constructs training data by starting with high-quality 'referenced pointwise' critiques (where GPT-4 sees the ground truth) and systematically removing references via prompting while retaining the specific insights
- Propagates fine-grained feedback from pointwise grading into pairwise comparison data, ensuring the model learns to justify rankings with specific details
- Uses a cross-validation mechanism to filter inconsistent labels between different construction paths, ensuring high-quality synthetic training data
Architecture
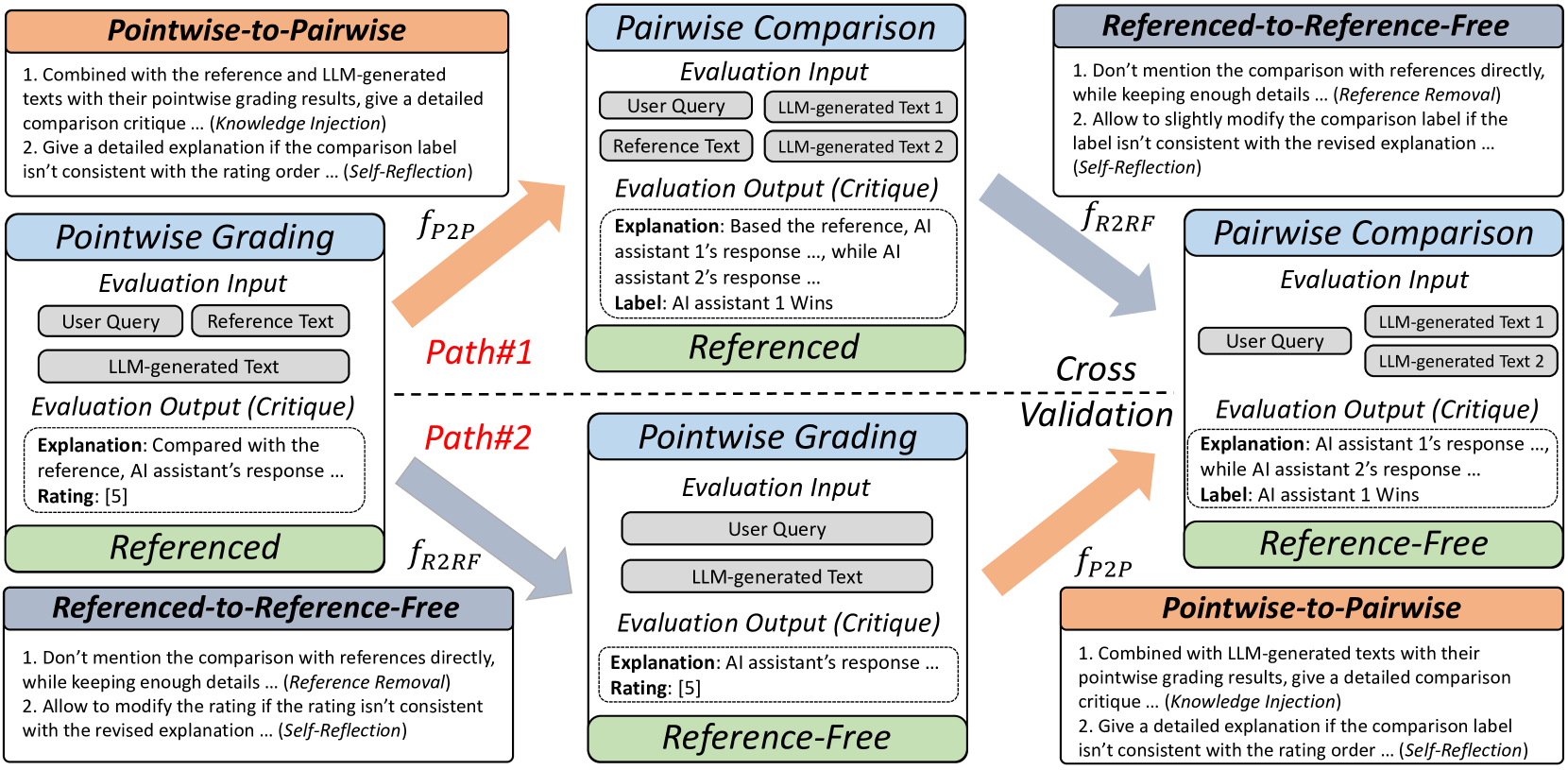
The Eval-Instruct data construction pipeline showing the multi-path prompting strategy.
Evaluation Highlights
- Outperforms GPT-3.5 (ChatGPT) and open-source baselines (Auto-J, JudgeLM) on correlation with human judgments across alignment benchmarks
- Achieves system-level correlation comparable to GPT-4 on pointwise grading tasks
- Critiques generated by CritiqueLLM successfully improve ChatGPT's generation quality via scalable feedback (Constitutional AI style)
Breakthrough Assessment
8/10
Significant methodology for synthesizing high-quality evaluation data without human labeling. Demonstrates that open-source models can rival GPT-4 in evaluation capability through clever data construction.