📝 Paper Summary
Modular Visual Question Answering
Code Generation for Vision
Neuro-symbolic AI
ProViQ answers zero-shot video questions by using an LLM to generate Python programs that invoke a library of pre-trained visual modules (detection, tracking, captioning) to reason procedurally.
Core Problem
Existing video QA methods rely on end-to-end training on limited datasets, struggling to generalize to new questions (zero-shot) or handle complex procedural reasoning steps.
Why it matters:
- Current supervised models fail to generalize outside their training distributions (e.g., from Kinetics to NeXT-QA)
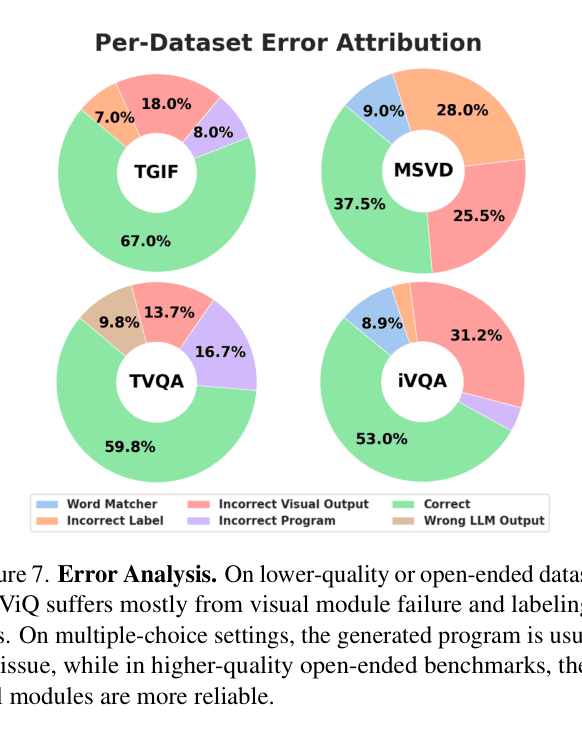
- End-to-end black-box models lack interpretability, making it hard to diagnose whether errors come from perception or reasoning
- Humans solve video queries procedurally (find frame -> find object -> check attribute), but standard models cannot explicitly execute these discrete steps
Concrete Example:
Question: 'What color jacket did the skier in orange pants wear?' An end-to-end model might guess based on the most common skier jacket color. ProViQ generates code to: 1) filter frames for skiers, 2) find the skier with orange pants, 3) crop that skier, and 4) query the jacket color.
Key Novelty
Procedural Video Querying (ProViQ)
- Extends visual programming (like ViperGPT) to the video domain by introducing a video-specific API (tracking, transcriptions, temporal filtering)
- Treats video QA as code generation: an LLM writes a Python script that calls pre-trained vision tools to solve the question step-by-step
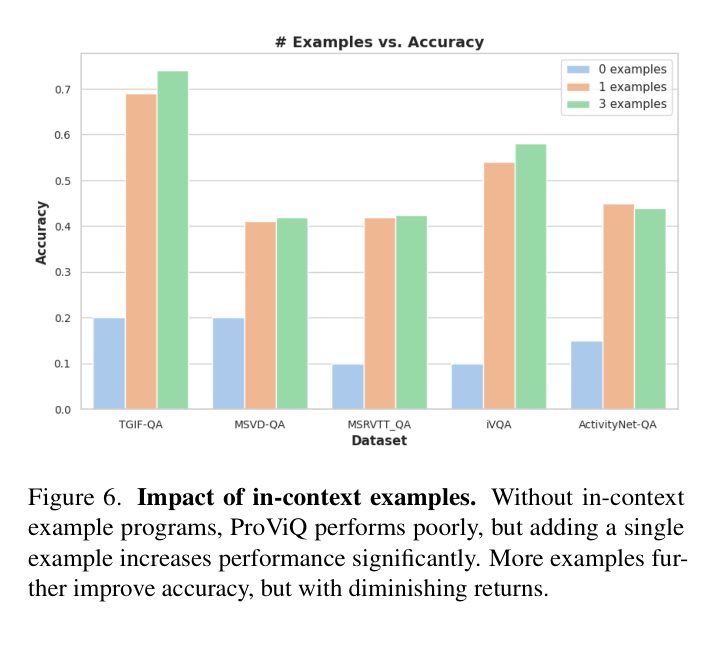
- Uses 'in-context learning' with example programs in the prompt to teach the LLM how to use the custom video API without any model training
Architecture
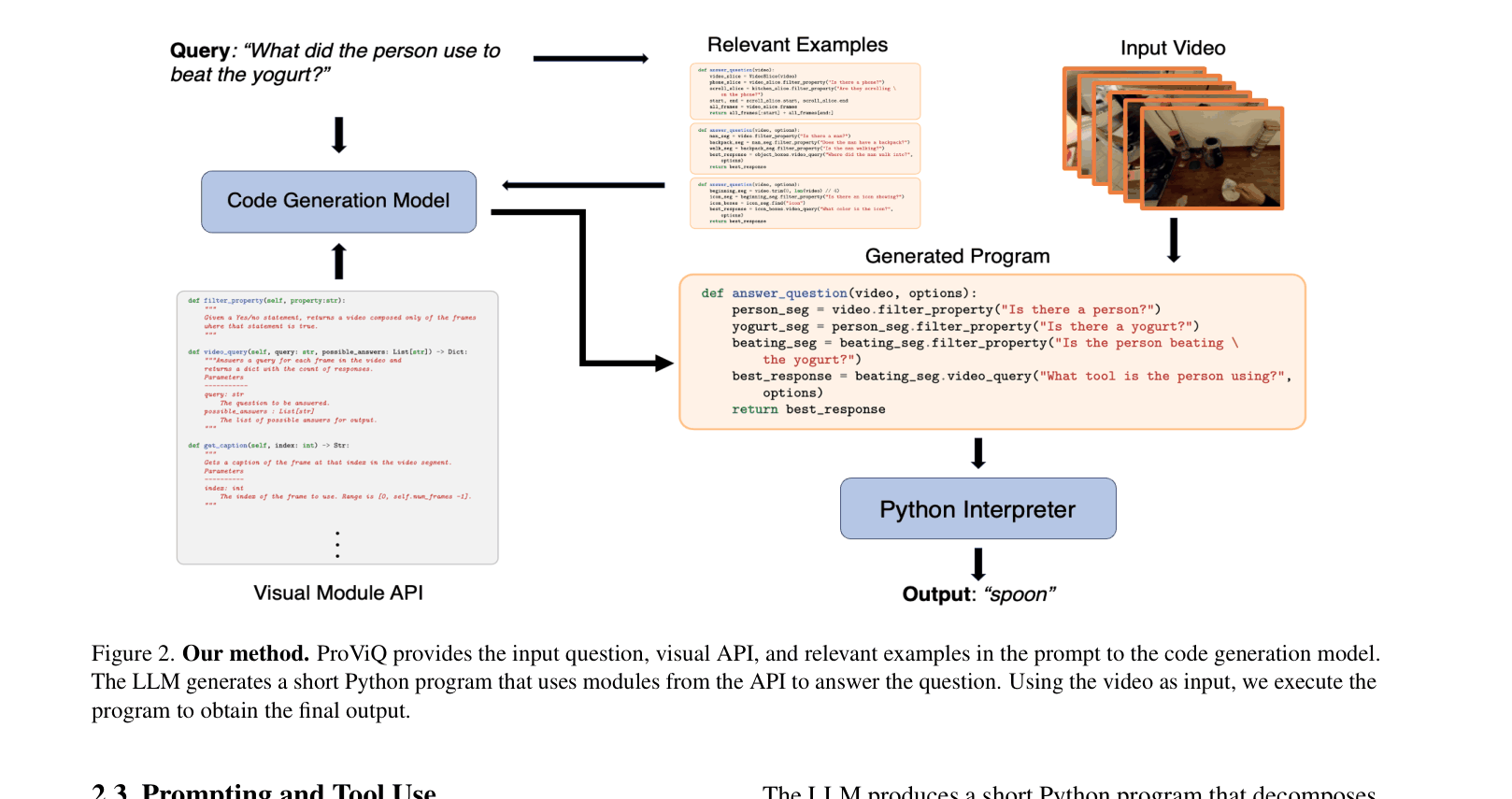
The ProViQ pipeline: Prompt Construction -> LLM Code Generation -> Program Execution -> Answer.
Evaluation Highlights
- +25% accuracy improvement on the ActivityNet-QA open-ended benchmark compared to previous zero-shot methods
- +25% accuracy gain on the challenging long-form EgoSchema benchmark over prior state-of-the-art
- Achieves state-of-the-art zero-shot performance across 7 different video QA benchmarks, including open-ended, multiple-choice, and multimodal datasets
Breakthrough Assessment
8/10
Significant leap in zero-shot performance (+25%) by successfully adapting code-generation techniques to video. Demonstrates that modular, training-free approaches can outperform supervised baselines on complex reasoning tasks.