📝 Paper Summary
Modularized RAG pipeline
Factuality
Chain-of-Note improves RAG robustness by generating sequential reading notes for retrieved documents to assess relevance before answering, allowing the model to filter noise or admit ignorance.
Core Problem
Standard RAG models often fail when retrieved documents are irrelevant or noisy, leading to hallucinations or overlooking intrinsic knowledge, and struggle to admit ignorance ('unknown') when neither retrieved nor internal knowledge is sufficient.
Why it matters:
- Retrievers are not guaranteed to yield pertinent information, and irrelevant data can mislead the generation process.
- State-of-the-art LLMs tend to hallucinate on fact-oriented questions rather than acknowledging limitations.
- Direct answer generation lacks transparency and often over-relies on retrieved context even when it is incorrect.
Concrete Example:
Query: 'who is the singer of never say never'. If the retriever fetches a document about 'The Fray' (irrelevant to the Justin Bieber song implied), a standard RAG might hallucinate an answer based on that document. CoN would note the document discusses The Fray, realize it's irrelevant, and either use internal knowledge (Justin Bieber) or say 'unknown'.
Key Novelty
Chain-of-Note (CoN)
- Instead of directly generating an answer from documents, the model first generates a 'reading note' for each retrieved document.
- These notes explicitly evaluate the document's relevance to the query and identify critical information or contradictions.
- The final answer is synthesized from these notes, allowing the model to filter out irrelevant content or default to 'unknown' if no valid information is found.
Architecture
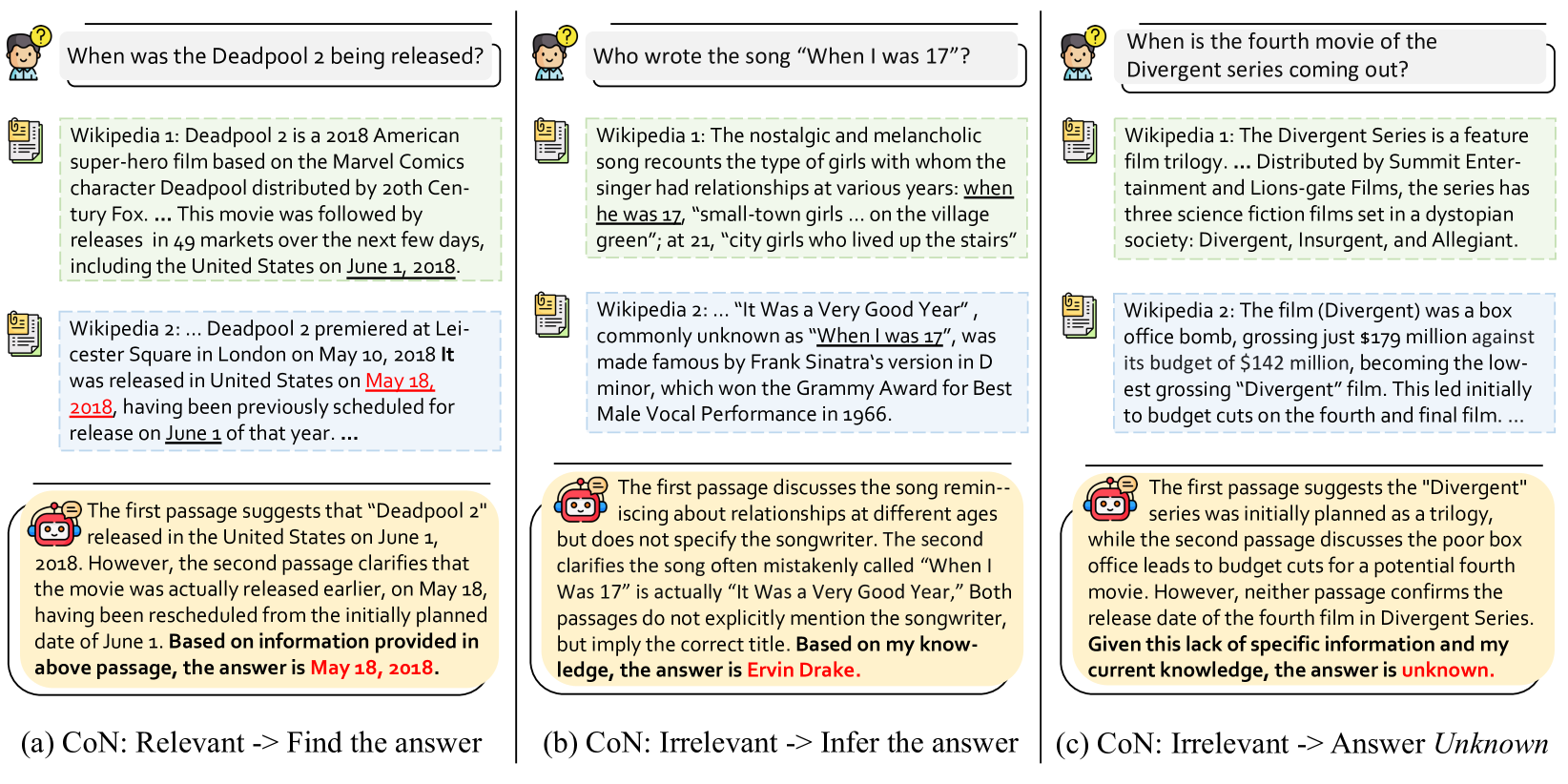
Illustration of the Chain-of-Note process for three different scenarios: (a) Relevant document found, (b) Contextual but not direct answer found, (c) Irrelevant documents found.
Evaluation Highlights
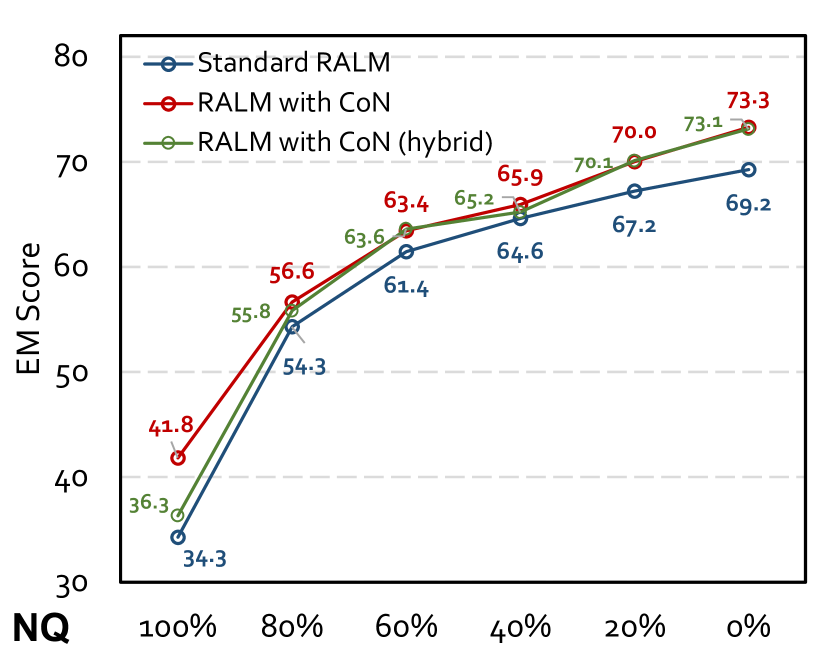
- +7.9 average improvement in Exact Match (EM) score on completely noisy retrieved documents across three open-domain QA datasets compared to standard RALM.
- +10.5 improvement in rejection rate (RR) on RealTimeQA for questions outside the model's pre-training scope, effectively reducing hallucinations.
- Outperforms Chain-of-Thought (CoT) prompting with GPT-4 in retrieval-augmented scenarios.
Breakthrough Assessment
8/10
Simple yet highly effective method tackling two critical RAG failures (noise and unknown scenarios) with significant empirical gains. The note-taking intermediate step provides interpretability and robustness.