📝 Paper Summary
Hallucination suppression
Knowledge misalignment
Factuality in LLMs
SEAL introduces a training objective that allows models to reject tokens misaligned with their internal knowledge via a special abstention token, combined with a decoding strategy that penalizes uncertainty.
Core Problem
Supervised fine-tuning (SFT) often introduces new factual knowledge that the pre-trained model does not possess (knowledge misalignment). Forcing the model to learn these unknown samples encourages fabrication and hallucination.
Why it matters:
- Knowledge misalignment between pre-training and fine-tuning is a primary cause of hallucinations in LLMs
- Standard SFT forces models to blindly imitate all ground-truth answers, even for facts they don't know, leading to overfitting on misaligned knowledge
- Existing solutions like filtering data or using self-generated data are either hard to scale (model-specific annotation) or lack quality guarantees
Concrete Example:
If an LLM knows 'Barack Obama' but not 'Javier Alva Orlandini', standard SFT forces it to memorize facts about Javier. Later, when asked about another unknown entity like 'Bob Dylan's occupation', the model might hallucinate 'Australia Journalist' because it learned to fabricate facts rather than relying on its parametric knowledge.
Key Novelty
SEAL (SElective Abstention Learning)
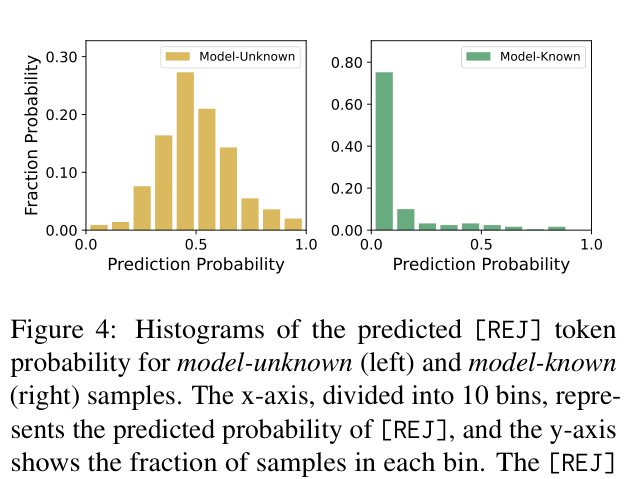
- Introduce a special [REJ] token during training that absorbs probability mass when the model's prediction conflicts with the ground truth, allowing the model to 'abstain' rather than memorize unknown facts
- Use the learned probability of this [REJ] token during inference as a proxy for uncertainty to penalize low-confidence generation paths in beam search
Architecture
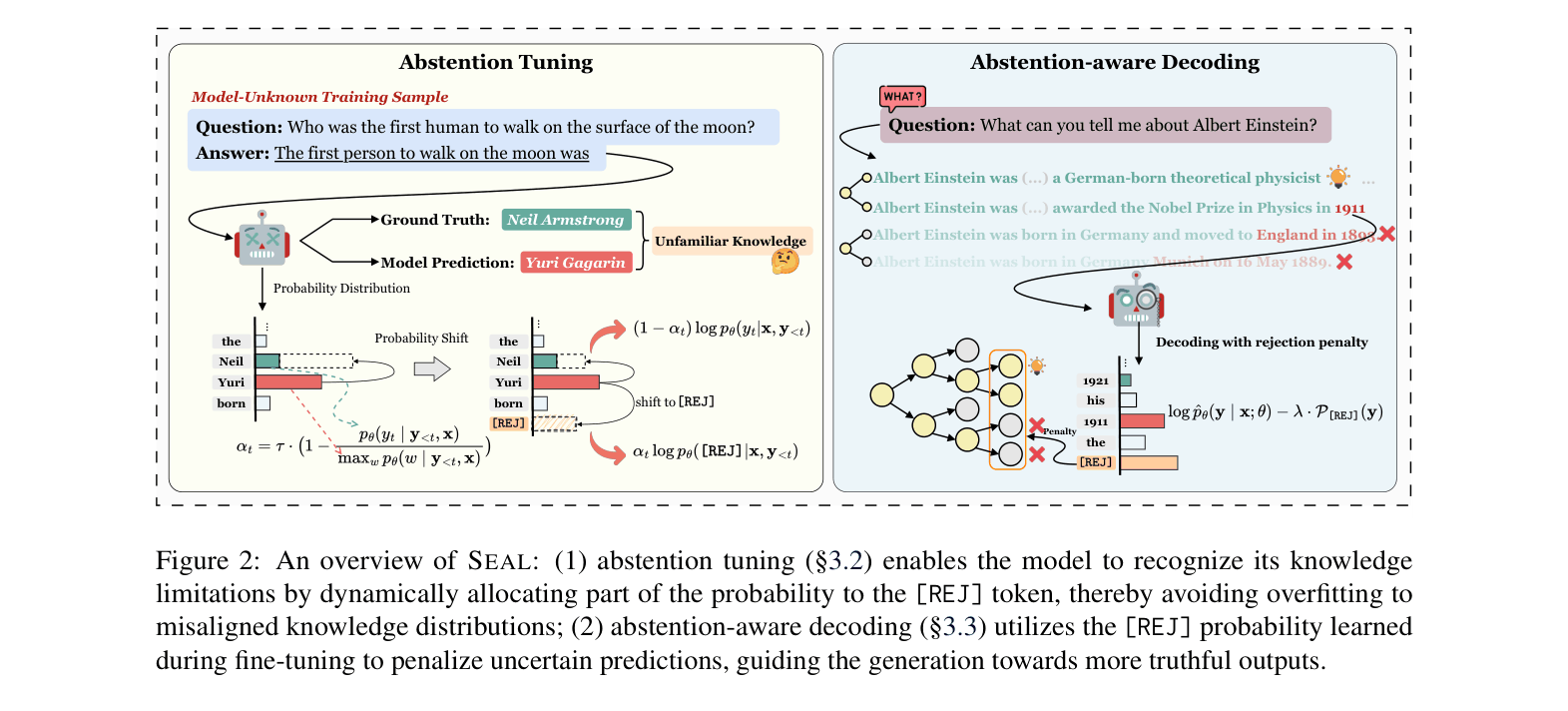
Overview of SEAL method illustrating Abstention Tuning and Abstention-aware Decoding.
Evaluation Highlights
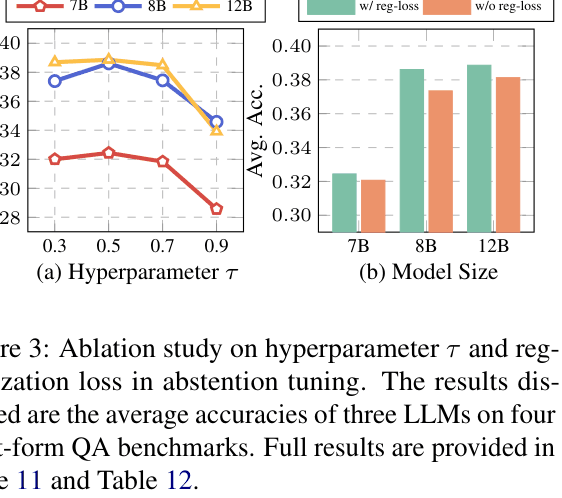
- +10.98% average accuracy improvement on short-form QA benchmarks for Llama-3-8B compared to standard SFT
- +19.24% improvement in FActScore on the Biography long-form QA dataset for Llama-3-8B compared to standard SFT
- Outperforms strong baselines like POPULAR and FLAME across Llama-3-8B, Mistral-7B, and Mistral-Nemo-12B on six datasets
Breakthrough Assessment
7/10
Strong empirical results tackling a specific, well-motivated problem (knowledge misalignment). The method is elegant and effective, though it relies on standard beam search modifications.