📝 Paper Summary
Factual Knowledge Injection
Interpretability & Analysis
Knowledge Internalization
By pre-training models on massive factually perturbed data (replacing entities with incorrect ones), this study reveals that the correctness of injected knowledge has negligible causal impact on downstream task performance.
Core Problem
Previous studies observe a correlation between factual knowledge injection and improved downstream performance, but have not established causality; improvements might stem from confounding factors rather than the knowledge itself.
Why it matters:
- If knowledge correctness doesn't matter, current research directions focusing on high-quality knowledge injection might be misguided
- Performance gains attributed to 'knowledge' might actually come from data domain, model size, or linguistic exposure
- Understanding what PLMs actually learn during knowledge injection is crucial for designing reliable AI systems
Concrete Example:
A model trained on 'Bill Gates is the CEO of Apple' (perturbed) performs statistically identically to one trained on 'Tim Cook is the CEO of Apple' (correct) on Named Entity Recognition tasks, suggesting the specific fact didn't drive the capability.
Key Novelty
Counterfactual Knowledge Perturbation Analysis
- Invert the standard evaluation: instead of trying to improve models, deliberately break the factual knowledge in the pre-training data at scale (up to 93% perturbation)
- Train models from scratch on this 'wrong' data using standard injection methods (masked modeling, entity embedding, adapter supervision)
- Compare downstream performance: if knowledge matters, the 'wrong' model should fail; if it performs equally well, the knowledge wasn't the cause of improvement
Architecture
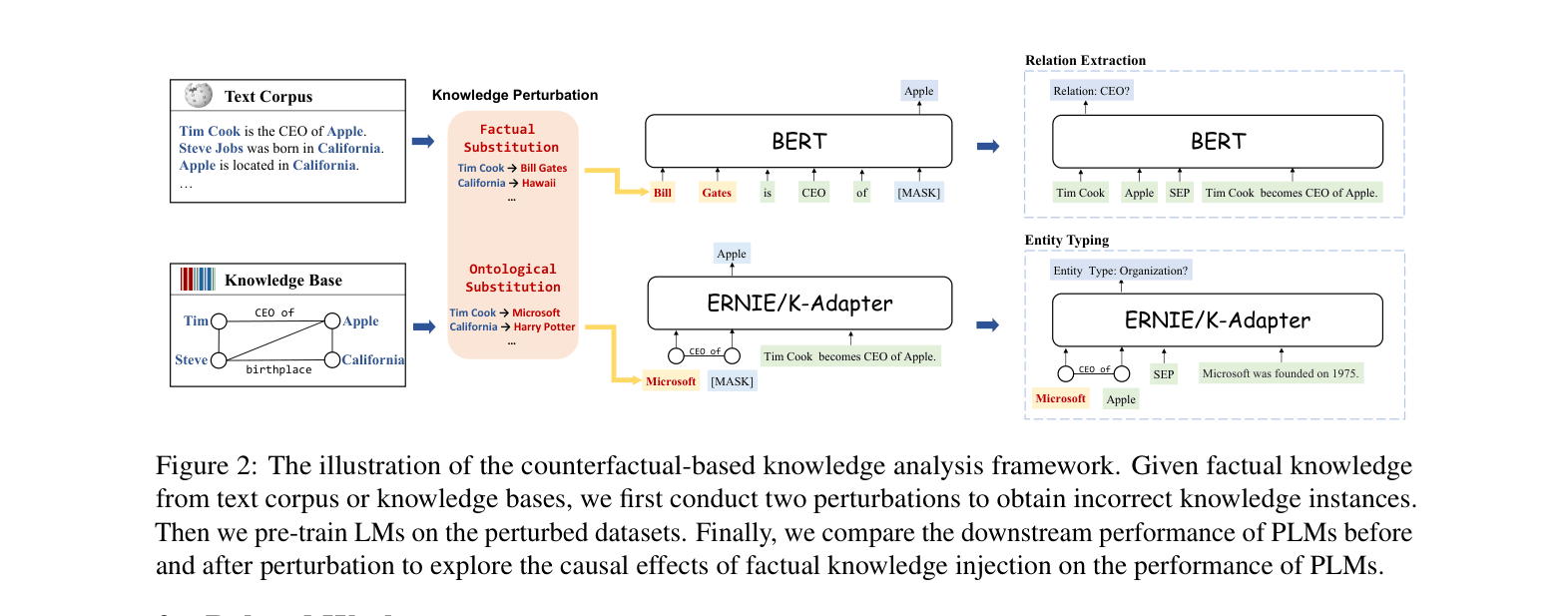
The counterfactual analysis framework flow: from data perturbation to pre-training to evaluation
Evaluation Highlights
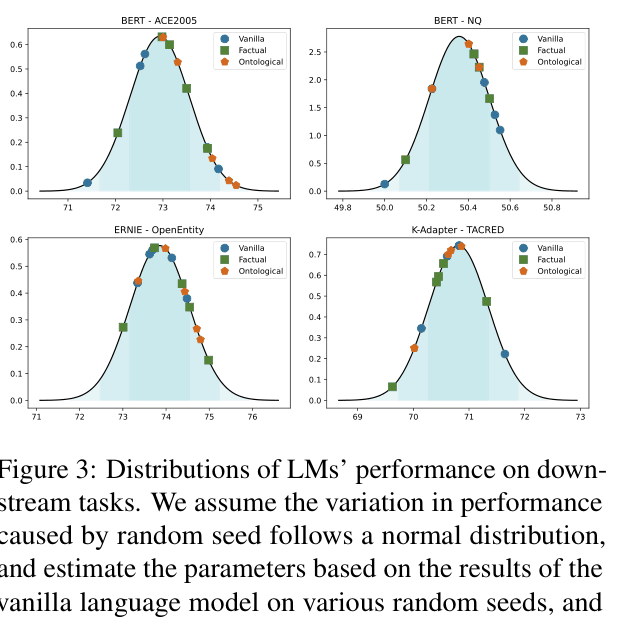
- No statistically significant difference (p > 0.05) in performance between vanilla and factually perturbed BERT models on 6 out of 7 downstream benchmarks (e.g., GLUE, SQuAD, NER)
- Perturbing 93% of Wikipedia facts caused LAMA knowledge probing accuracy to drop from 28.18% to 11.62%, yet downstream GLUE scores remained stable (80.26 vs 80.07)
- Even ontological perturbation (swapping entities with wrong types, e.g., Person → Location) failed to significantly degrade performance on most tasks, including entity typing
Breakthrough Assessment
8/10
A negative result that is highly significant. It challenges the fundamental assumption of a major subfield (knowledge injection), effectively showing that 'knowledge' gains are likely spurious correlations.