📝 Paper Summary
Table Recognition (TR)
Document Parsing
Self-Supervised Learning
TRivia improves table recognition models by fine-tuning vision-language models on unlabeled table images using reinforcement learning, where rewards are derived from the model's ability to answer synthesized questions about the table.
Core Problem
State-of-the-art table recognition relies on massive labeled datasets or proprietary APIs (like Gemini 2.5 Pro) that are costly, privacy-invasive, and unavailable for open-source training.
Why it matters:
- High-quality labeled table data (image-HTML pairs) is expensive and time-consuming to curate at scale
- Open-source models lag significantly behind proprietary models due to data scarcity
- Distilling from proprietary models is costly, violates service agreements, and caps performance at the teacher's level
Concrete Example:
When an open-source model like UniTable processes a complex real-world table, it often fails due to limited context window (448x448) and insufficient training data, while TRivia-3B can handle it by learning from unlabeled wild data via QA feedback.
Key Novelty
Self-Supervised TR via QA-based Reinforcement Learning
- Instead of needing ground-truth HTML labels, the model is rewarded if its table recognition output allows an external LLM to correctly answer questions about the table
- Uses a 'response-consistency' sampling strategy to select only the most informative unlabeled images (where the model is uncertain) for training
- Generates synthetic questions (QA pairs) using an attention-guided mechanism to ensure questions cover diverse parts of the table and are visually grounded
Architecture
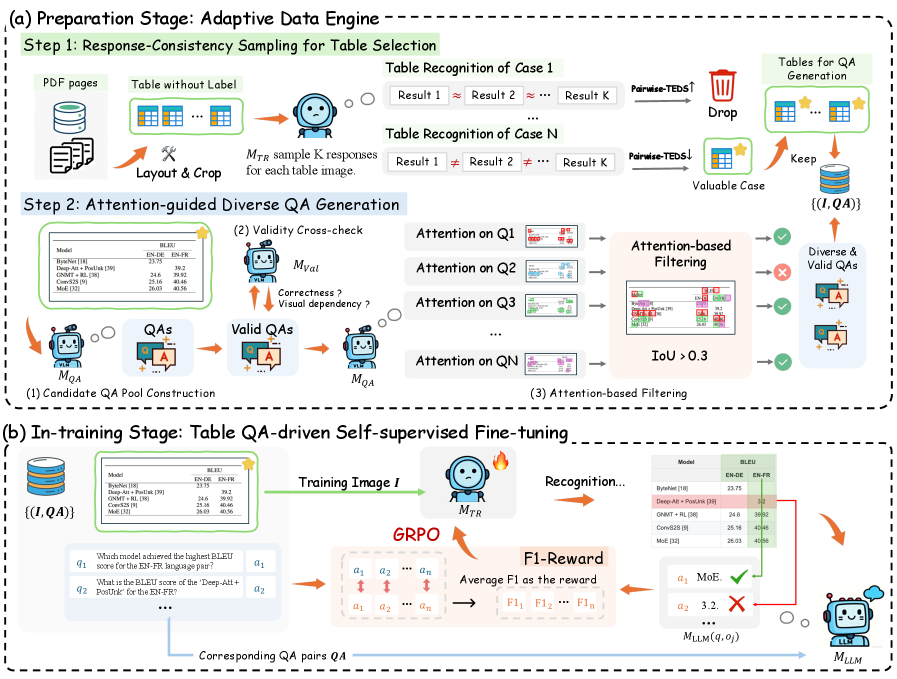
The TRivia framework overview, showing the data preparation stage (Question Generation) and the in-training stage (GRPO with QA rewards).
Evaluation Highlights
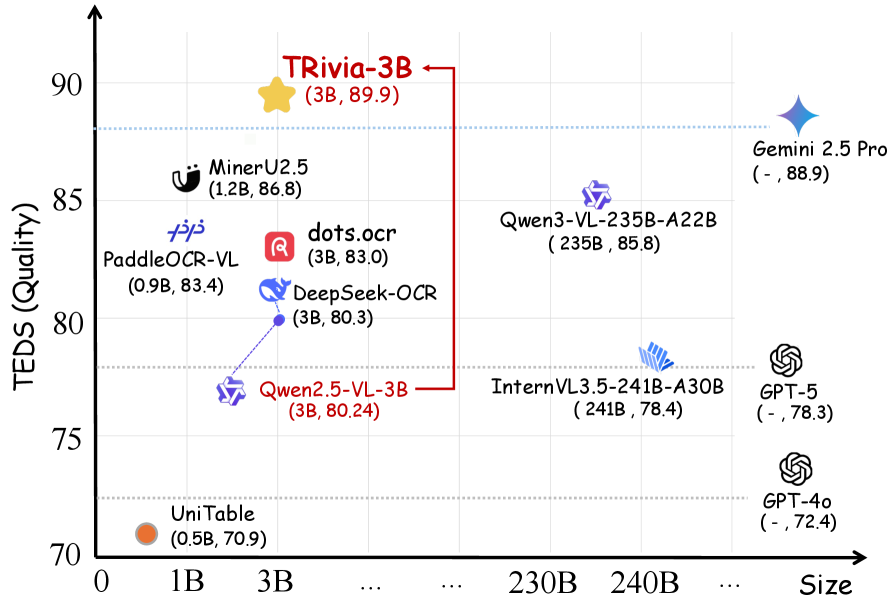
- Surpasses Gemini 2.5 Pro and GPT-5 on the CC-OCR benchmark (84.15 vs 79.46 TEDS)
- Outperforms MinerU2.5 (a 26B parameter model trained on millions of samples) using only a 3B parameter model
- Achieves 86.85 TEDS on OmniDocBench, beating Qwen2.5-VL-72B (81.65) despite being significantly smaller
Breakthrough Assessment
9/10
Demonstrates that a small 3B model can beat massive proprietary models (Gemini, GPT-5) on specialized tasks using only unlabeled data and self-supervision, a significant shift from the supervised/distillation paradigm.