📝 Paper Summary
Mixture-of-Experts (MoE)
Scaling Laws
Large Language Model (LLM) Efficiency
The paper introduces Efficiency Leverage to quantify the computational advantage of Mixture-of-Experts over dense models, deriving scaling laws that predict this advantage based on activation ratio, expert granularity, and compute budget.
Core Problem
While MoE models decouple parameter count from compute cost, predicting their effective capacity is unsolved; neither total nor active parameters reliably proxy performance, making it difficult to set realistic pre-training expectations.
Why it matters:
- Researchers cannot intuitively determine the 'equivalent capacity' of an MoE architecture before expensive training runs.
- Existing MoE scaling laws focus on isolated dimensions (like sparsity) rather than the interplay of multiple factors (granularity, compute budget).
- Efficiently allocating massive compute resources requires knowing which MoE configuration yields the highest performance gain over dense baselines.
Concrete Example:
A 16B parameter MoE might activate only 2.8B parameters per token. Is this equivalent to a 7B dense model or a 10B dense model? Without a unified metric, engineers cannot predict if this specific architecture justifies its complexity compared to a standard dense baseline.
Key Novelty
Efficiency Leverage (EL) Metric & Unified Scaling Law
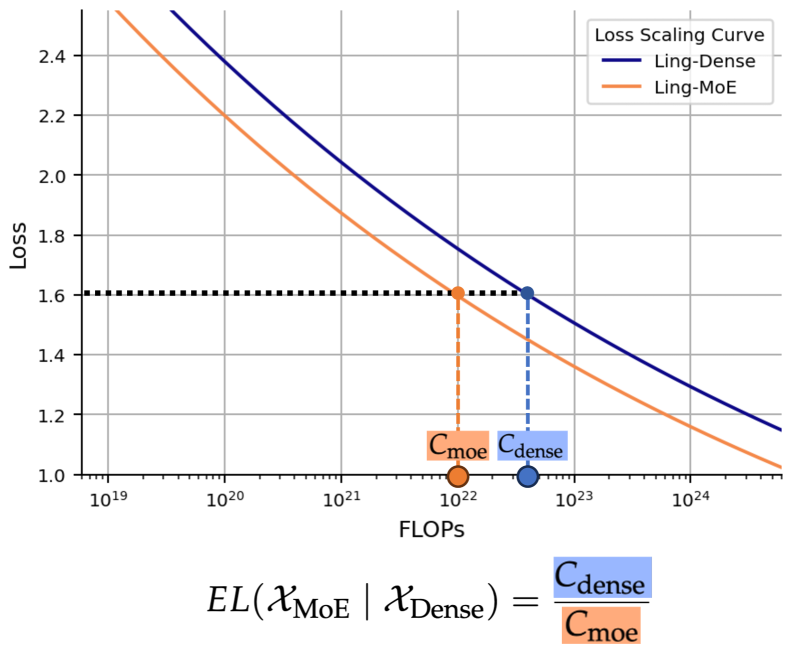
- Defines EL as the ratio of computational costs between a dense model and an MoE model achieving the same loss.
- Discovers that EL is primarily driven by activation ratio (power law) and compute budget (amplifying effect), while expert granularity acts as a non-linear modulator with an optimal range.
- Integrates these factors into a single formula to predict the efficiency gain of any MoE configuration.
Architecture
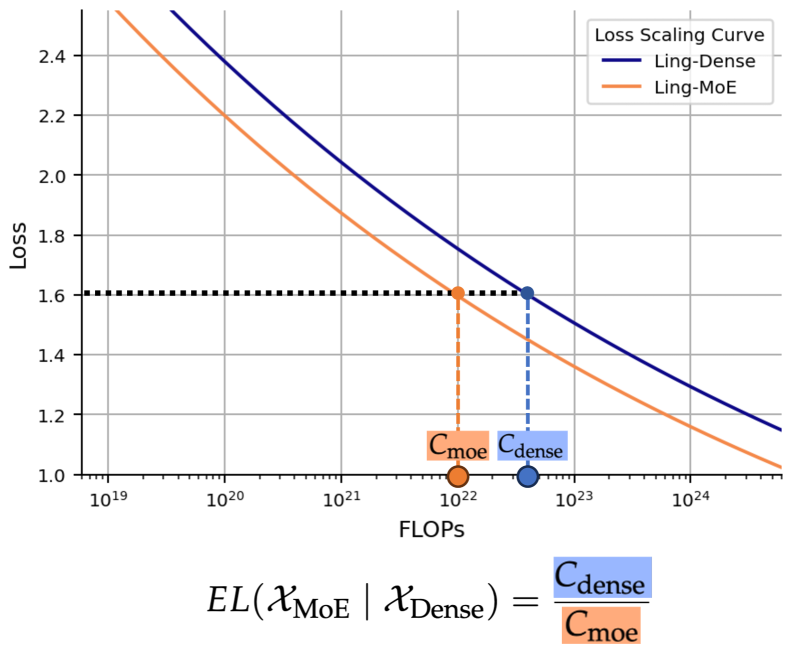
Conceptual illustration of Efficiency Leverage (EL). It plots Loss vs. Training FLOPs for both Dense and MoE models.
Evaluation Highlights
- Derived scaling law accurately predicted >7x efficiency leverage for a pilot model at 1e22 FLOPs budget.
- Validation model 'Ling-mini-beta' (0.85B active params) matched the performance of a 6.1B dense model while using ~7x less compute.
- Identified optimal expert granularity (ratio of model dimension to expert dimension) to be between 8 and 12 for standard load-balancing losses.
Breakthrough Assessment
8/10
Provides a comprehensive, empirically-backed formula for MoE design, moving beyond heuristics. The 7x efficiency validation is a strong practical proof point, though the scope is limited to decoder-only LLMs.