📝 Paper Summary
Knowledge Editing in LLMs
Model Evaluation
DepEdit evaluates whether knowledge editing methods can update facts in LLMs while respecting logical dependencies—specifically updating implied consequences of the edit without disrupting unrelated facts.
Core Problem
Existing knowledge editing evaluations focus only on specificity (editing a single fact without side effects) but neglect implication awareness (ensuring logical consequences of that edit are also updated).
Why it matters:
- LLMs used as knowledge bases must maintain internal logical consistency; changing a premise without updating its conclusion leaves the model in a contradictory state
- Current methods like MEND or ROME are optimized for local edits but their ability to propagate changes through logical rules is largely unmeasured
- Without testing for dependency, we cannot trust that an edited model correctly infers the downstream effects of new information
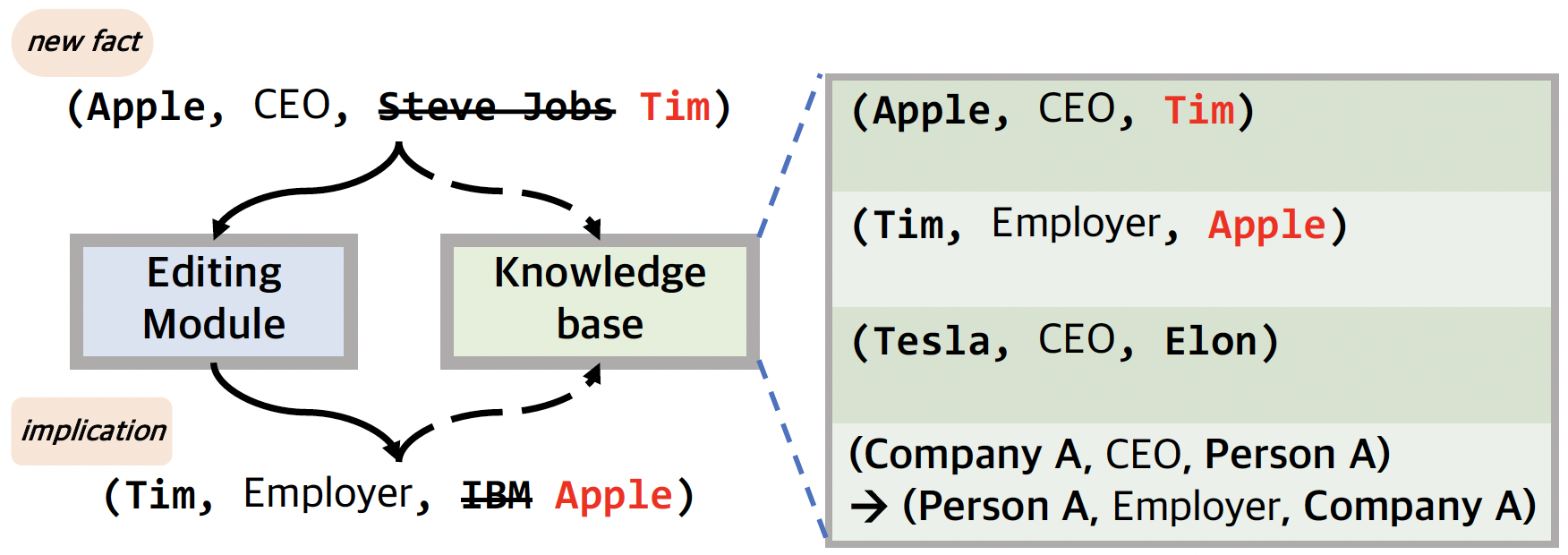
Concrete Example:
If we edit the fact (Apple, CEO, Steve Jobs) to (Apple, CEO, Tim Cook), the model must also update the implication (Tim Cook, Employer, Apple). Current methods might successfully change the CEO but fail to update the Employer field for Tim Cook, or wrongly alter unrelated facts like (Tesla, CEO, Elon Musk).
Key Novelty
Establish-and-Update Evaluation Protocol
- Simulates a controlled environment where an LLM first 'establishes' a set of facts and logical rules, then undergoes an 'update' phase where specific facts are edited
- Evaluates editing success not just on the target fact, but on 'implication awareness' (does the model infer the logical result?) and 'specificity' (are unrelated facts preserved?)
- Uses a new dataset (DepEdit) containing triplets of (Fact, Rule, Implication) to rigorously test these dependencies
Architecture
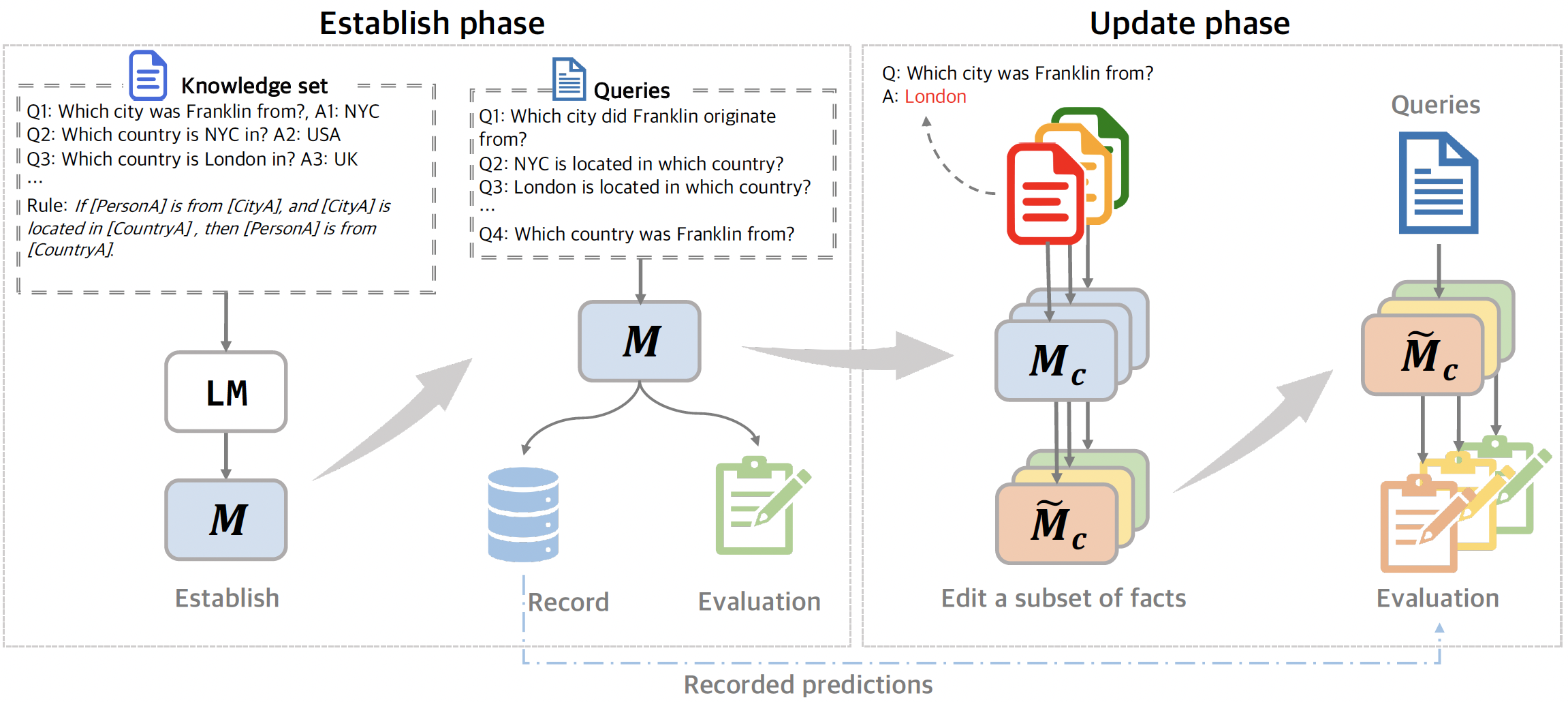
The Establish-and-Update Evaluation Protocol. It visualizes the two phases: (1) Prompting the model with a Knowledge Set K to 'Establish' facts/rules, and (2) Editing a specific fact and measuring the impact on the fact itself, its implications, and unrelated facts.
Evaluation Highlights
- State-of-the-art editing methods (MEND, ROME) achieve high scores on specificity (>90%) but struggle significantly with implication awareness (<30% success on implied facts)
- Existing methods are highly sensitive to surface forms; they can edit exact matches but often fail when the question phrasing changes slightly (lexical variations)
- Gradient analysis reveals that optimization-based editors often fail to find the correct direction to update parameters for logical implications
Breakthrough Assessment
7/10
Crucial critique of the current knowledge editing landscape. While it doesn't propose a new editing method, the protocol exposes a fundamental flaw (lack of logical propagation) in existing SOTA methods.