📝 Paper Summary
Modularized RAG pipeline
DAMF adapts a search query generator to new domains without human labels by using retrieval scores from a trained RAG model as reinforcement learning rewards.
Core Problem
Search query producers trained on one domain struggle in new domains, but obtaining human annotations for every new domain is costly.
Why it matters:
- Existing weak supervision methods (using BM25 scores as rewards) fail when commercial search engines return noisy web pages (ads/irrelevant info)
- Conversations vary significantly; some turns don't require external knowledge, and forcing query generation on these turns hurts model performance
- Commercial search engines are often black boxes, making direct gradient propagation impossible, necessitating robust reinforcement learning approaches
Concrete Example:
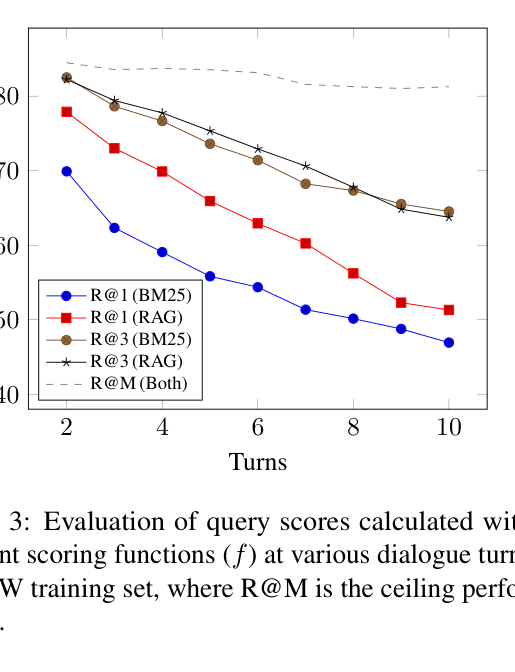
In a dialogue about 'Miyun Reservoir', the conversation shifts to 'Tianzhuang Reservoir'. A BM25-based system incorrectly scores queries about the old topic highly due to word overlap. The proposed RAG-based feedback correctly identifies 'Tianzhuang Reservoir' as the better query because it retrieves documents that actually help generate the correct response.
Key Novelty
Domain Adaptation with Model Feedback (DAMF)
- Replaces surface-level BM25 rewards with deep semantic feedback from a trained Retrieval-Augmented Generation (RAG) model to guide the query producer
- Filters training instances where generated queries are indistinguishable or low-quality, preventing the model from learning from noise or unnecessary search turns
- Uses knowledge distillation from the source-domain model to regularize training, ensuring the policy doesn't drift too far from a good initialization
Architecture
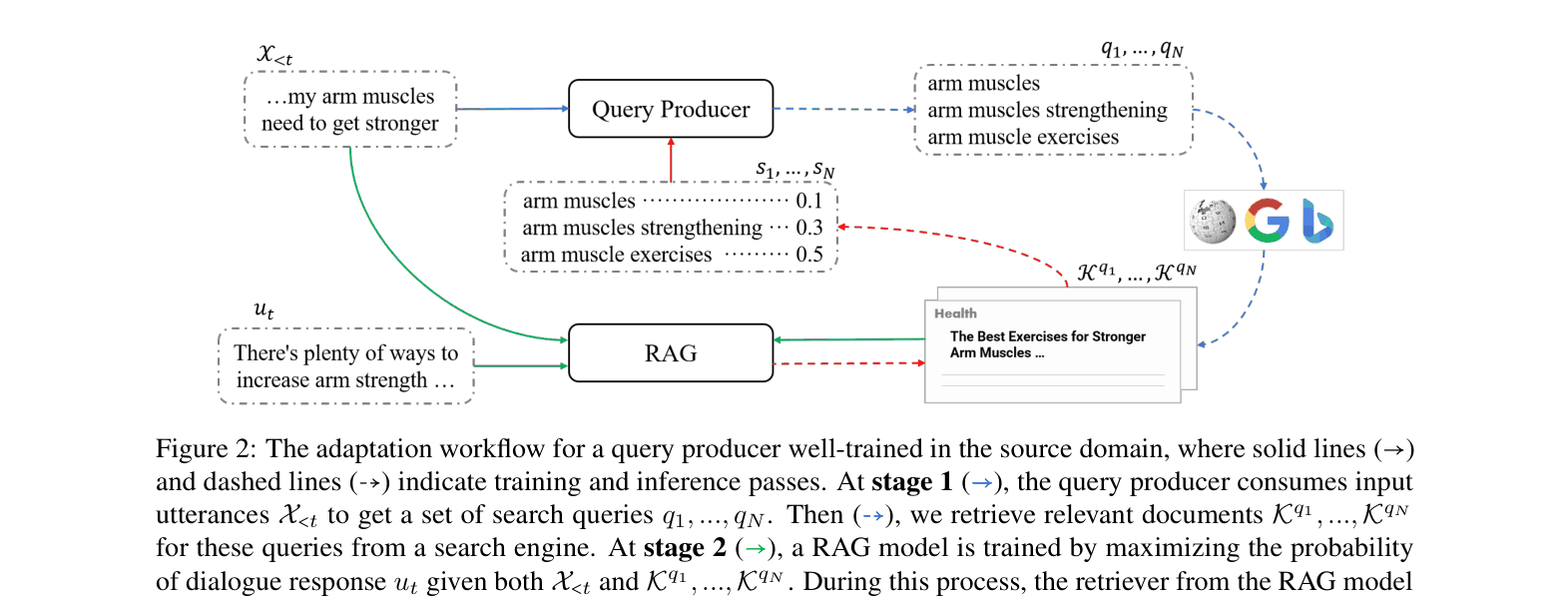
The 3-stage domain adaptation workflow: (1) Generating candidate queries and retrieving documents (offline cache); (2) Training a RAG model on target data to learn document relevance; (3) Tuning the query producer via RL using RAG scores as rewards.
Evaluation Highlights
- +3.17 Unigram F1 improvement over strong Self-Training baselines on the noisy DuSinc -> KdConv domain adaptation setting
- Significantly outperforms BM25-based feedback methods (WSMF), improving R@1 by ~2.4% in clean settings and Unigram F1 by ~3.2% in noisy settings
- Achieves higher query quality than 8-shot in-context learning with text-davinci-003 (GPT-3.5) on target domains
Breakthrough Assessment
7/10
Solid improvement over existing weak supervision for query generation. Replacing BM25 with RAG feedback is logical and effective, though the framework relies on existing RL and KD techniques.