📝 Paper Summary
Modularized RAG pipeline
Retrieval granularity
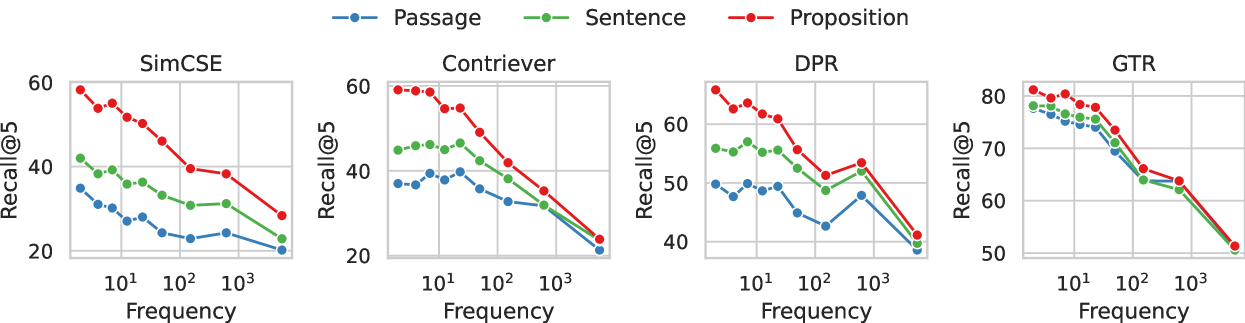
Indexing retrieval corpora by 'propositions'—atomic, self-contained factoids—significantly improves dense retrieval and downstream QA performance compared to using fixed-length passages or sentences.
Core Problem
Standard retrieval units like 100-word passages often contain irrelevant details that distract models, while sentences lack necessary context (like coreference resolution) to be understood independently.
Why it matters:
- Irrelevant details in retrieved passages consume context window space and can confuse generation models in RAG pipelines
- Sentence-level retrieval fails when sentences depend on surrounding text for meaning (e.g., 'He did it' is meaningless without knowing who 'He' is)
- Dense retrievers often fail to generalize to new domains when indexed on coarse units that dilute the density of relevant information
Concrete Example:
A passage about the Leaning Tower of Pisa contains details about restoration and displacement. A question asks about the 'current lean'. A full passage retrieves irrelevant history. A sentence 'it leans 3.99 degrees' misses the context that 'it' refers to the tower. A proposition 'The Leaning Tower of Pisa currently leans at about 3.99 degrees' is precise and self-contained.
Key Novelty
Proposition-Level Retrieval
- Decompose text into 'propositions': atomic, self-contained statements of fact that resolve coreferences (e.g., replacing 'he' with the entity name) and isolate distinct pieces of meaning
- Index the corpus at this fine-grained level, allowing the retriever to match queries directly to precise facts rather than noisy passages or context-poor sentences
- Use these compact units in RAG prompts to increase the density of relevant information within a fixed token budget
Architecture
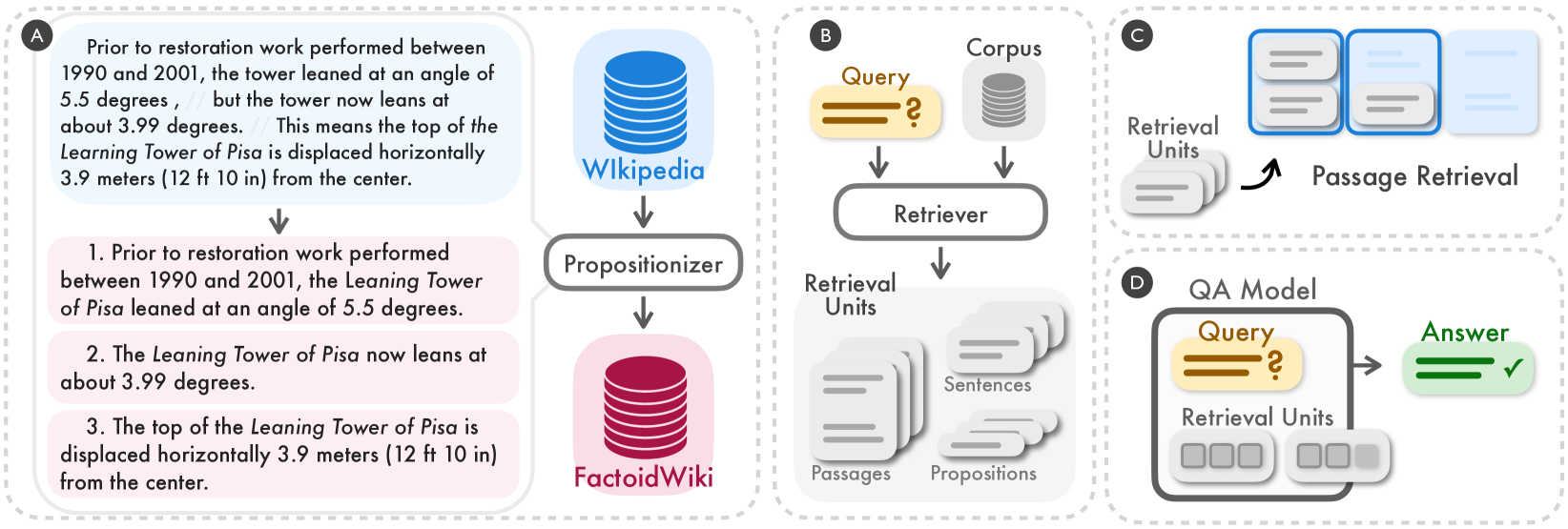
Comparison of different retrieval granularities: Passage vs. Sentence vs. Proposition. It illustrates how a passage is split into propositions.
Evaluation Highlights
- +12.0 Recall@5 improvement on average across 5 QA datasets using unsupervised SimCSE when indexing by propositions instead of passages
- +10.1 average Recall@20 improvement for unsupervised retrievers and +2.7 for supervised retrievers over passage-based indexing
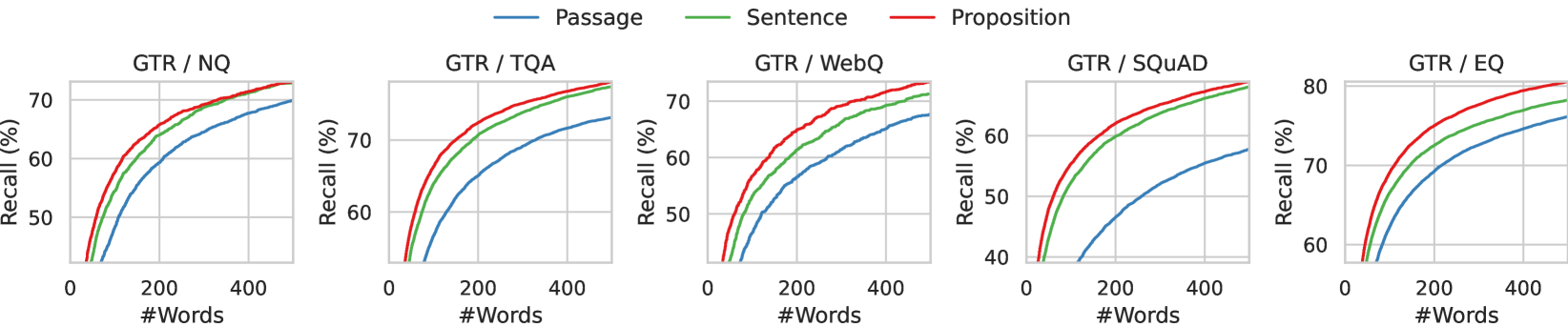
- Achieves higher downstream QA accuracy with fewer tokens: GTR with propositions outperforms passages by +2.8 EM@500 on LLaMA-2-7B
Breakthrough Assessment
7/10
Simple yet highly effective intervention at the data indexing level. Strong empirical gains, particularly for unsupervised retrieval and cross-task generalization, without requiring retriever retraining.