📝 Paper Summary
Benchmark datasets
Hallucination detection
Retrieval-Augmented Generation (RAG)
RAGTruth provides a large-scale, manually annotated dataset of word-level hallucinations in RAG responses, demonstrating that fine-tuning smaller models on this data outperforms prompting GPT-4 for detection.
Core Problem
Existing hallucination datasets are often synthetic, small-scale, or not specific to RAG settings, making it difficult to detect subtle inconsistencies between retrieved context and generated responses.
Why it matters:
- LLMs frequently generate unsupported or contradictory claims even when provided with correct retrieved documents
- Current detection methods rely on synthetic data that differs from natural hallucinations, limiting real-world applicability
- Lack of high-quality training data prevents the development of specialized, small-model hallucination detectors
Concrete Example:
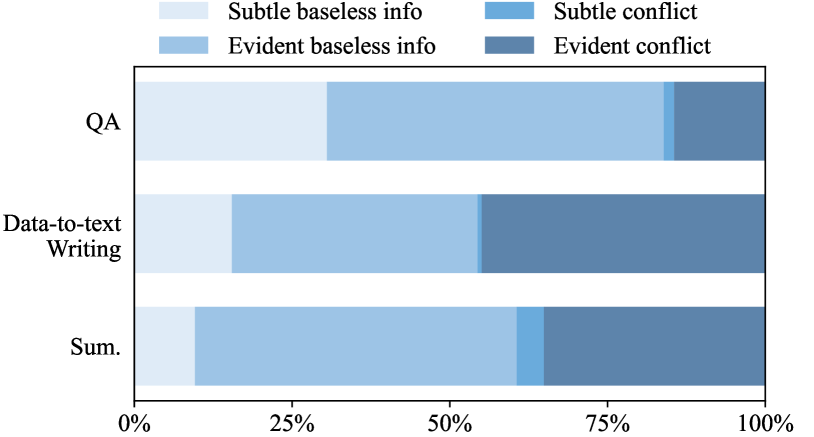
In a data-to-text task involving restaurant details, a model might correctly list amenities but hallucinate that the restaurant 'accepts credit cards' when the retrieved JSON context (BusinessParking, OutdoorSeating, etc.) never mentions payment methods.
Key Novelty
RAGTruth Dataset & Taxonomy
- Constructs a corpus of nearly 18,000 naturally generated responses from diverse LLMs (including GPT-4, Llama-2, Mistral) across three RAG tasks: QA, data-to-text, and summarization
- Introduces a granular 4-type taxonomy for RAG hallucinations: Evident Conflict, Subtle Conflict, Evident Baseless Information, and Subtle Baseless Information
- Demonstrates that a relatively small open-source model (Llama-2-13B) fine-tuned on this data can detect hallucinations better than large proprietary models (GPT-4) using prompting
Architecture

The data generation and annotation pipeline for RAGTruth.
Evaluation Highlights
- Fine-tuned Llama-2-13B achieves 39.5% F1 on span-level detection, significantly outperforming GPT-4 (14.2% F1) and SelfCheckGPT (4.0% F1)
- Fine-tuned detector achieves 86.8% F1 on response-level classification, surpassing GPT-4 (71.3% F1)
- Using the fine-tuned model to filter responses reduces hallucination rate in Llama-2-13B-Chat responses from ~33% to ~9% on the test set
Breakthrough Assessment
9/10
Significant contribution due to the scale and quality of manual annotation (18k responses). The finding that specialized small models beat GPT-4 at detection is practically valuable for efficient RAG deployment.