📝 Paper Summary
Multimodal Recommendation
Disentangled Representation Learning
Explainable AI
AD-DRL improves recommendation interpretability by explicitly forcing disentangled factors to correspond to specific item attributes (e.g., brand, price) rather than learning abstract latent factors.
Core Problem
Existing disentangled recommendation methods learn abstract latent factors without clear semantic meanings, making it difficult to understand or control which specific aspects (e.g., style vs. price) influence recommendations.
Why it matters:
- Lack of semantic clarity limits system interpretability—users don't know why an item was recommended (e.g., is it for the brand or the price?).
- Unsupervised disentanglement hinders controllability; users cannot easily adjust preferences to focus on specific attributes like 'dresses ignoring price'.
- Traditional methods fail to leverage explicit attribute labels available in multimodal data to guide the learning of robust representations.
Concrete Example:
If a user selects a dress, a standard model might learn a latent factor mixing 'brand' and 'price'. AD-DRL explicitly separates these, allowing the system to recommend items specifically because they match the 'brand' preference, independent of 'price'.
Key Novelty
Attribute-Driven Disentangled Representation Learning (AD-DRL)
- Assigns specific semantic attributes (like 'category' or 'popularity') to chunks of the embedding vectors, forcing the model to learn factors that are semantically meaningful rather than abstract.
- Uses a hierarchical disentanglement approach: first separating factors within and across modalities (high-level), then refining them by predicting specific attribute values (low-level) to capture fine-grained details.
- Aligns multimodal features (text and image) for the same attribute while contrasting them against different attributes to ensure consistency.
Architecture
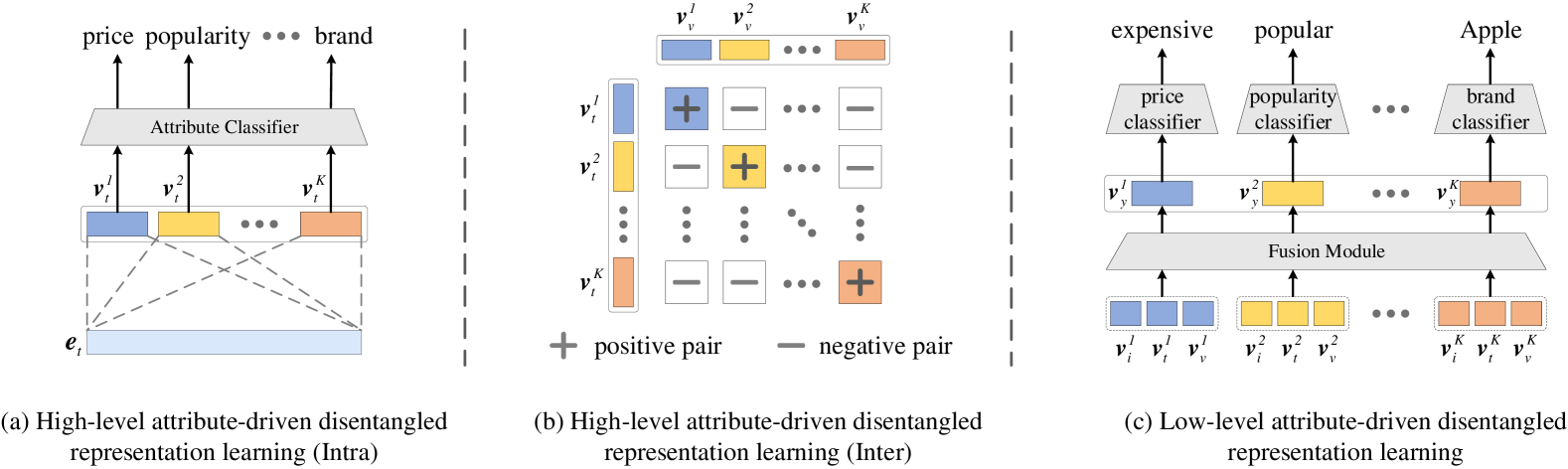
The overall architecture of AD-DRL, illustrating the three main disentanglement modules.
Evaluation Highlights
- Outperforms state-of-the-art baselines like DRML and MMGCN on three real-world datasets (Clothing, Sports, Baby), showing robust recommendation accuracy.
- Demonstrates high interpretability: visualization shows distinct clusters for attributes like 'category', confirming the model successfully disentangles semantic factors.
- Enables controllability: the model can effectively filter recommendations based on specific user attribute preferences (e.g., retrieving items matching a specific category preference).
Breakthrough Assessment
6/10
Solid contribution applying attribute supervision to disentanglement, addressing a key limitation (interpretability) of prior unsupervised methods. Results are good, though the core technique is a logical extension of existing disentanglement frameworks.
