📝 Paper Summary
Language Model Fine-tuning
Knowledge Distillation
Aggressive Fine-tuning
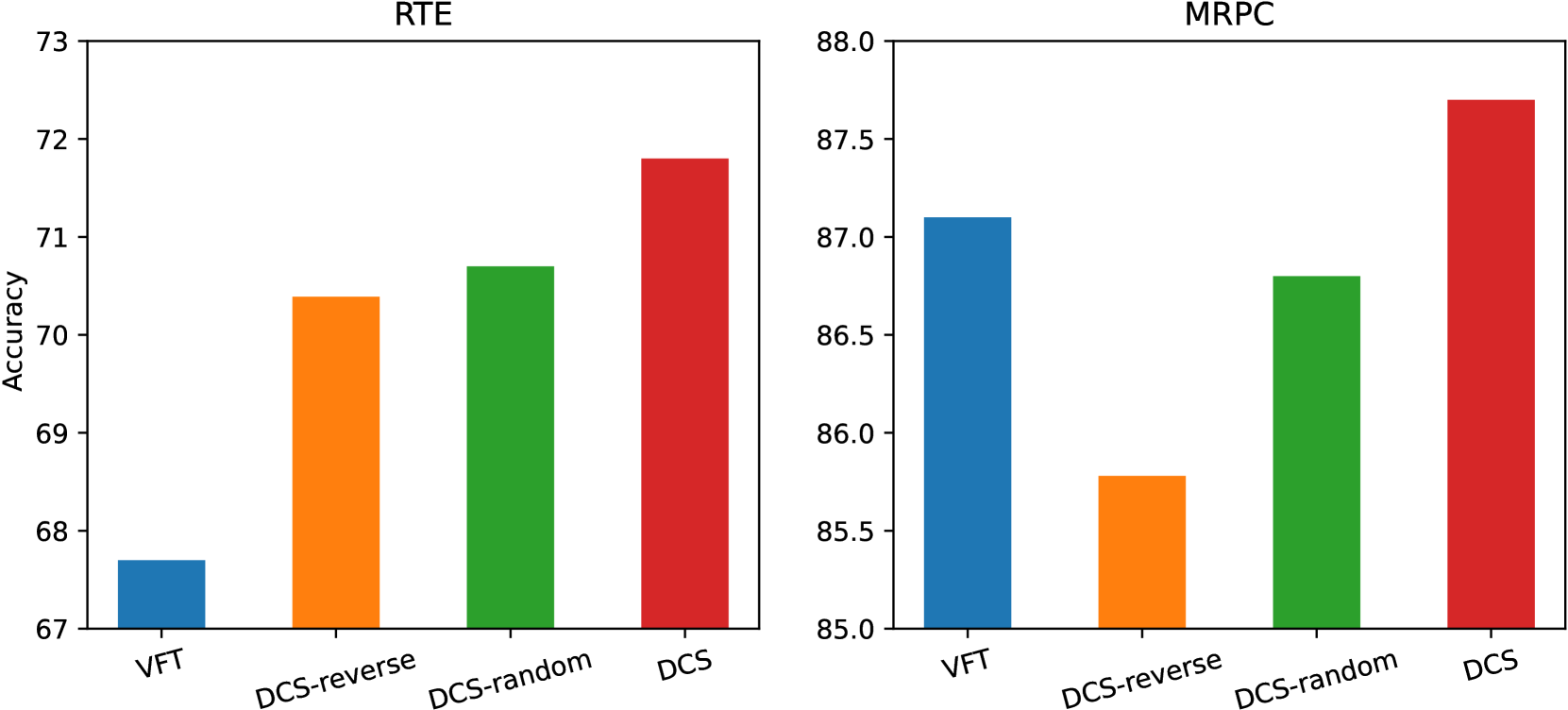
DCS improves fine-tuning on small datasets by dynamically re-weighting training samples where a student model disagrees with a teacher model of the same architecture.
Core Problem
Aggressive fine-tuning of large pre-trained language models on limited labeled downstream data leads to overfitting and reduced generalization.
Why it matters:
- Fine-tuning large models on small datasets is a standard practice but notoriously unstable and prone to overfitting.
- Existing solutions like adapters or noise injection often add complexity or limit model flexibility.
- Simple distillation potentials are overlooked as a fine-tuning regularizer.
Concrete Example:
When fine-tuning BERT on the small RTE dataset (2.5K samples), the model may overfit to easy examples and fail to generalize, whereas DCS forces it to focus on 'hard' samples where it disagrees with a teacher.
Key Novelty
Dynamic Corrective Self-Distillation (DCS)
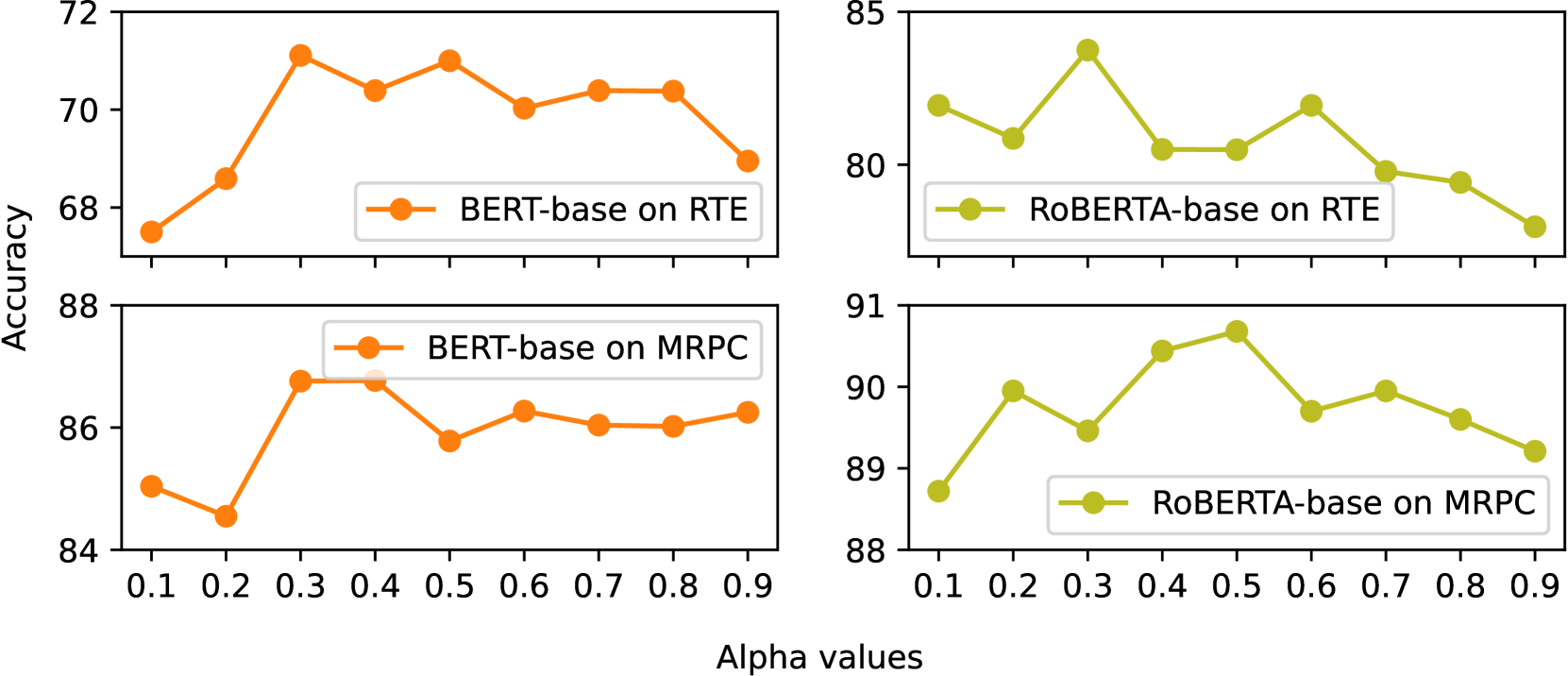
- Inspired by adaptive boosting, DCS iteratively adjusts the weight of each training sample during fine-tuning.
- It uses a self-distillation setup where a teacher (same architecture) guides the student.
- Weights are increased for 'discordant' samples—instances where the student's prediction differs from the teacher's—forcing the student to focus on correcting its own errors.
Architecture
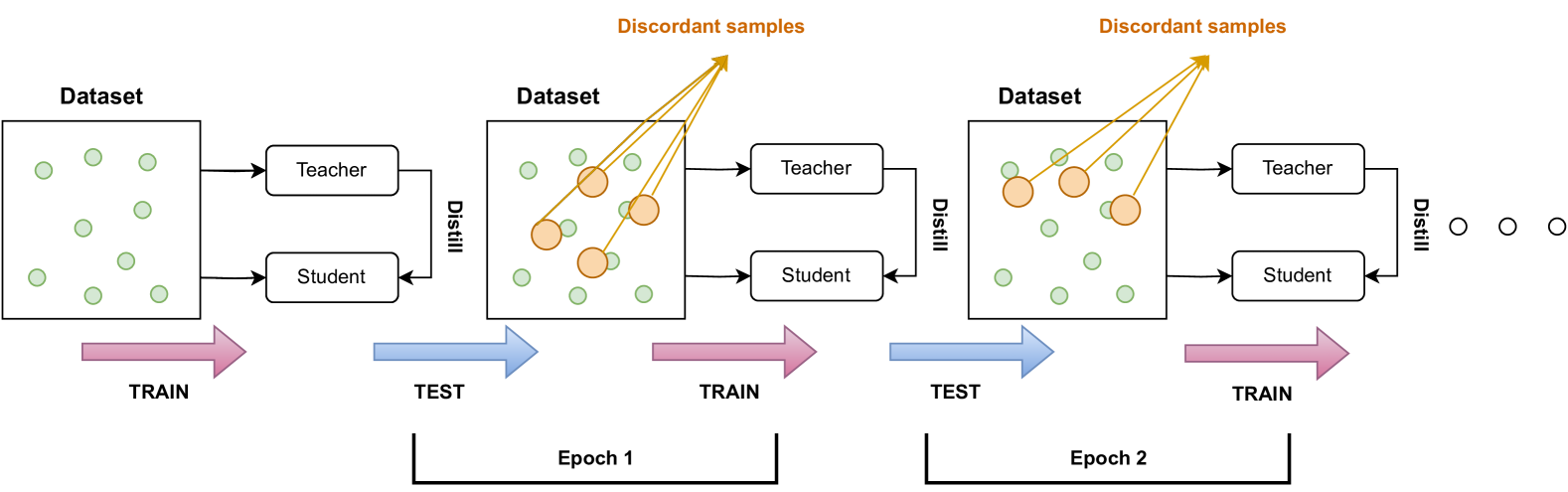
The DCS framework framework illustrating the teacher-student interaction.
Evaluation Highlights
- +1% average improvement across GLUE benchmark tasks using BERT-base compared to vanilla fine-tuning.
- +8% improvement on the RTE dataset (a small dataset) with ELECTRA compared to vanilla fine-tuning.
- Outperforms or matches existing methods like R3F and Child-Tuning on BERT-large.
Breakthrough Assessment
4/10
A solid, incremental improvement for fine-tuning stability on small datasets. The method is simple and effective, but relies on standard distillation principles and boosting concepts applied to PLMs.