📝 Paper Summary
Memory recall
Efficient transformers
CAT is a transformer architecture that decodes tokens by attending to parallelly compressed representations of past chunks, allowing a single model to trade off quality and compute at test-time.
Core Problem
Standard transformers have quadratic attention costs, while efficient alternatives (sparse/linear attention) often sacrifice in-context recall or require fixed compute budgets that cannot adapt to varying task requirements.
Why it matters:
- Diverse downstream tasks have different resource needs; a single fixed-budget model is suboptimal for both low-latency email replies and high-recall code completion.
- Existing efficient methods often use heuristic attention masks or complex recurrent states that struggle with long-context information retention.
- Training multiple models for different efficiency trade-offs is prohibitively expensive.
Concrete Example:
Code auto-completion requires high-recall access to function names defined far back in a repository (demanding dense attention), whereas short email replies need low latency (sufficing with linear attention). Current methods force a choice before training, preventing a single model from handling both optimally.
Key Novelty
Compress & Attend Transformer (CAT)
- Splits sequences into chunks and compresses each chunk in parallel into a compact representation using a 'compressor' transformer.
- Decodes new tokens by attending only to these compressed past representations and the current raw chunk, significantly reducing memory and compute.
- Enables test-time adaptivity by training with variable chunk sizes; a single model can switch between high-efficiency (large chunks) and high-quality (small chunks) modes instantly.
Architecture
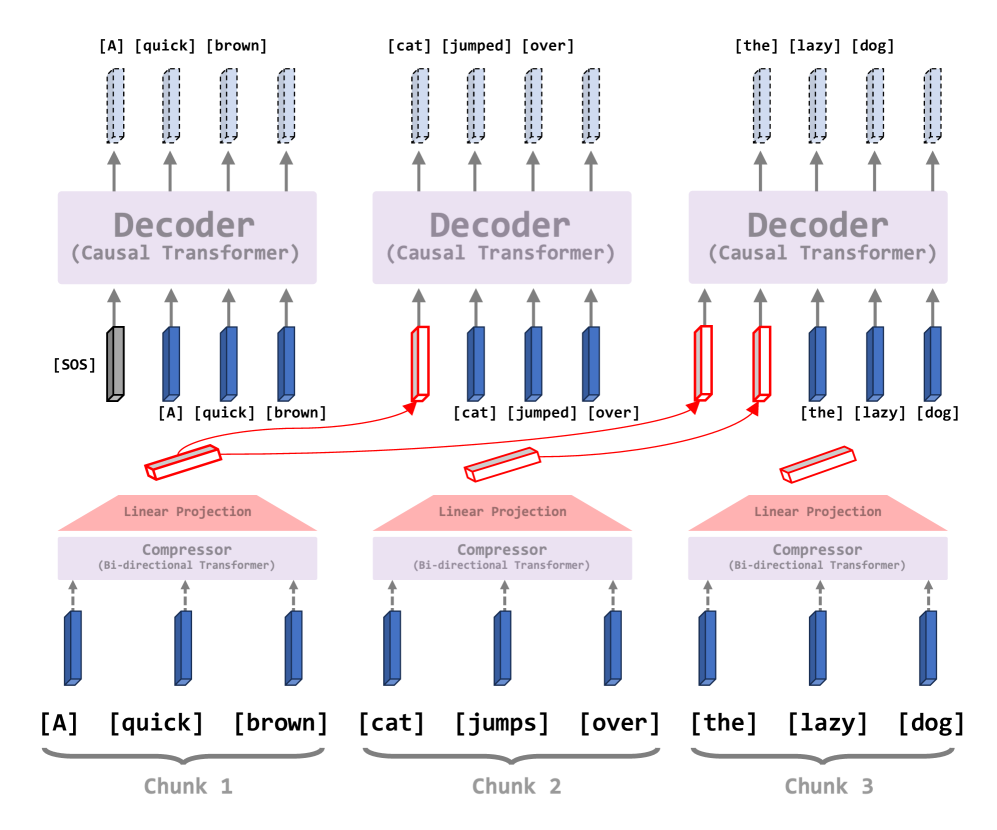
The CAT architecture layout showing parallel compression and autoregressive decoding.
Evaluation Highlights
- Matches dense transformer perplexity on FineWeb-Edu while being 1.4-3x faster and requiring 2-9x lower total memory.
- Surpasses dense transformer on real-world in-context recall tasks even in its least efficient setting (cat-4), while being 1.5x faster and 2x more memory efficient.
- Outperforms linear attention baselines (Mamba2, GatedDeltaNet) and hybrid architectures on long-context understanding benchmarks.
Breakthrough Assessment
9/10
Offers a rare combination of superior performance and efficiency compared to dense transformers, with the unique capability of test-time compute-quality interpolation in a single model.