📝 Paper Summary
Data Pruning / Coreset Selection
Multimodal Pretraining (CLIP)
Density-Based Pruning (DBP) reduces web-scale multimodal datasets by clustering embeddings and selecting difficult examples based on cluster density and proximity to other clusters, achieving higher performance with significantly less data.
Core Problem
Training foundation models like CLIP on massive web-scale datasets (e.g., LAION-2B) is prohibitively expensive and inefficient because much of the data is redundant or low-quality.
Why it matters:
- High computational and environmental costs of training large-scale models limit research to well-funded industry labs.
- Existing pruning methods like CLIP-score filtering focus on individual sample quality but ignore the marginal information gain relative to other samples in the dataset.
Concrete Example:
A dataset might contain thousands of nearly identical images of 'golden retrievers'. Random sampling or simple CLIP-score filtering might keep hundreds of these redundant examples, wasting compute, while under-sampling sparser concepts like specific rare birds.
Key Novelty
Density-Based Pruning (DBP)
- Clusters dataset embeddings using k-means and calculates a 'complexity' score for each cluster based on its density (intra-cluster distance) and isolation (inter-cluster distance).
- Allocates a target number of samples to each cluster proportional to its complexity, then selects the 'hardest' (least prototypical) samples from each cluster to fill that quota.
Architecture
Conceptual flow of the Density-Based Pruning method.
Evaluation Highlights
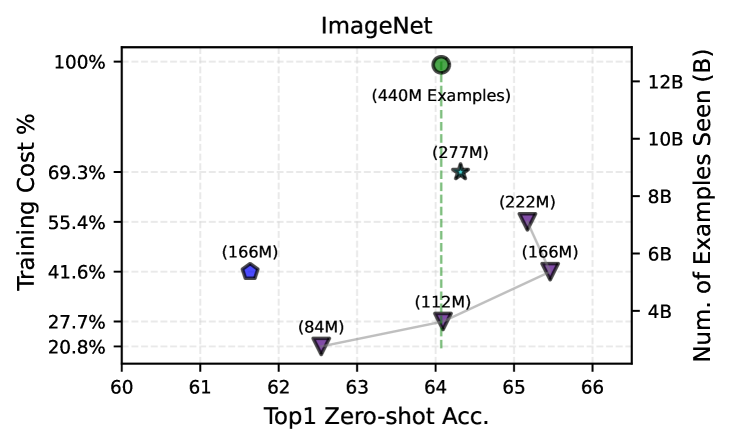
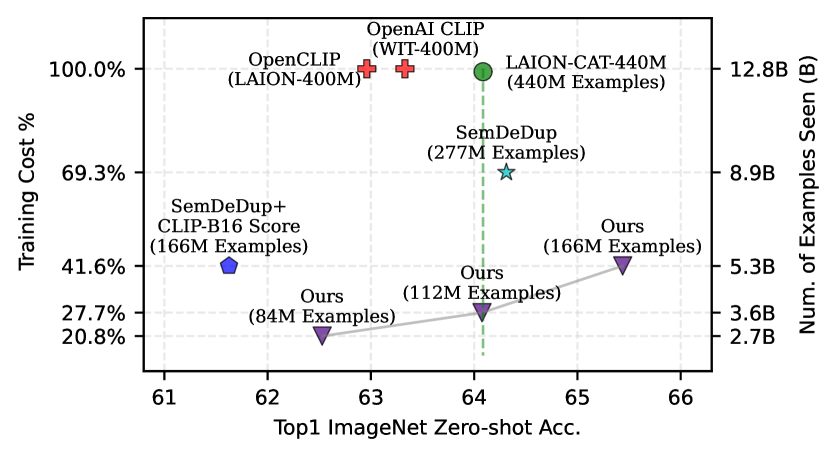
- +1.1 percentage points ImageNet zero-shot accuracy over OpenCLIP-ViT-B/32 baseline while using only 27.7% of the training data/compute.
- Achieves new state-of-the-art ImageNet zero-shot accuracy on DataComp Medium benchmark compared to T-MARS and other baselines.
- Outperforms training on the full LAION-CAT-440M dataset on retrieval and VTAB tasks despite using only ~50% of the training compute.
Breakthrough Assessment
8/10
Significantly improves data efficiency for CLIP training, effectively challenging the 'more data is better' scaling law by showing careful pruning beats full-scale training.