📝 Paper Summary
Incremental Learning (IL)
Catastrophic Forgetting
The paper demonstrates that Pre-trained Language Models do not suffer from catastrophic forgetting during sequential fine-tuning; rather, performance drops because the classification head's embeddings drift, which can be fixed by simple freezing strategies (SEQ*).
Core Problem
Current research assumes Pre-trained Language Models (PLMs) inherently suffer from catastrophic forgetting during Incremental Learning (IL), leading to complex methods that may underestimate the model's native abilities.
Why it matters:
- Most existing IL methods are designed based on the false premise that PLMs forget old knowledge, leading to unnecessary complexity.
- Simple baselines like Sequential Fine-tuning (SEQ) are widely regarded as weak lower bounds, but their failure modes are misunderstood.
- Understanding where forgetting actually occurs (backbone vs. classifier) is crucial for efficient continual learning systems.
Concrete Example:
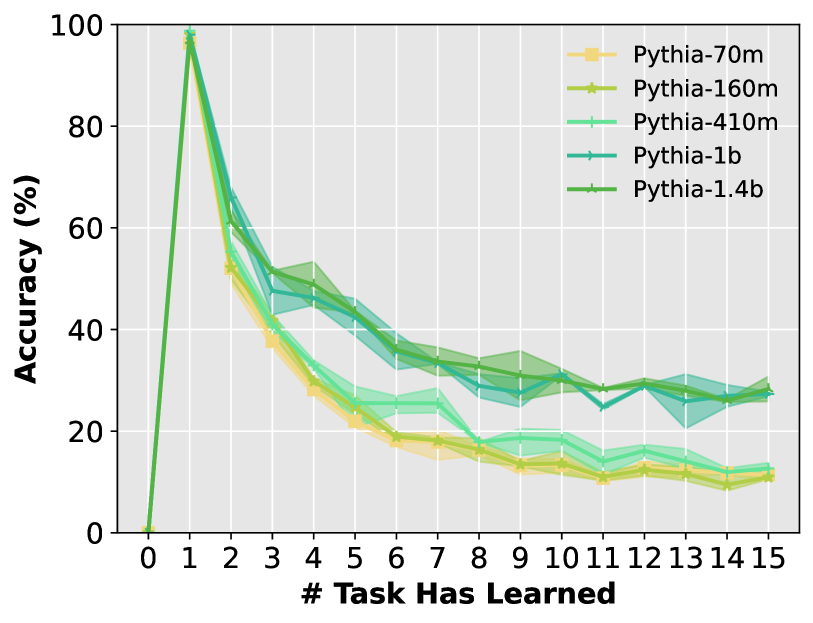
In a Class-Incremental Learning setting on intent classification, a standard fine-tuned model's accuracy drops from ~98% to ~10% as new tasks are added. However, probing shows the backbone still retains the information to classify all tasks correctly; only the linear classifier head has 'forgotten' how to map features to old classes.
Key Novelty
SEQ* (Improved Sequential Fine-tuning)
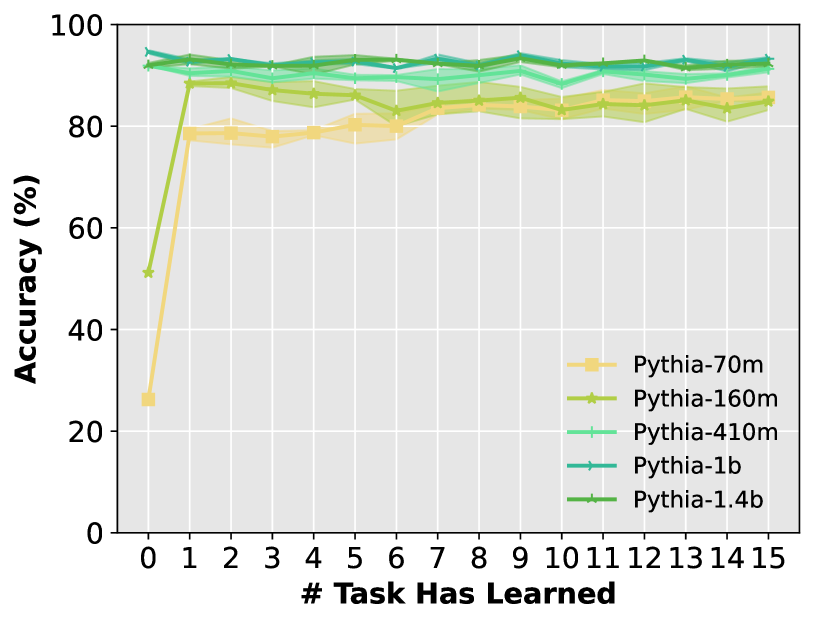
- Re-evaluates forgetting using linear probing, revealing that PLM backbones retain knowledge even after sequential fine-tuning on new tasks.
- Identifies that 'forgetting' is primarily a classifier alignment issue: old class embeddings are pushed away from optimal positions while new ones dominate.
- Proposes SEQ*: a simple method that freezes the PLM backbone after an initial warm-up and freezes old classifier heads, outperforming complex SOTA methods.
Architecture
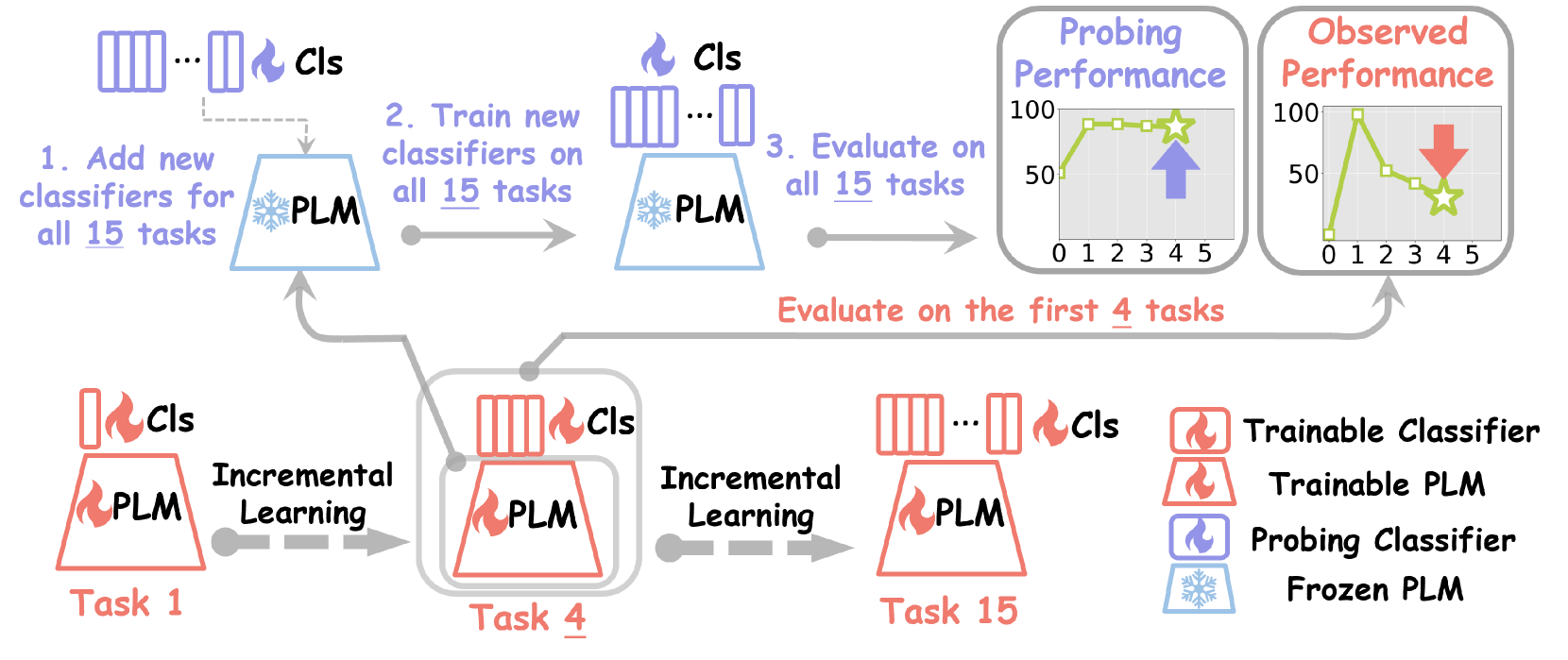
Illustration of the Probing Assessment framework vs. Standard Observation.
Evaluation Highlights
- On Class-Incremental Learning (CIL) for intent classification (CLINC150), SEQ* achieves ~93% accuracy with BERT-Large, outperforming SOTA method ELF (~90%) and standard SEQ (~15%).
- Linear probing reveals PLM backbones maintain high accuracy (near 100% on some tasks) throughout sequential training, contradicting the catastrophic forgetting hypothesis.
- SEQ* reduces trainable parameters significantly compared to expansion-based methods while matching or beating replay-based methods without storing old data.
Breakthrough Assessment
7/10
Challenge fundamental assumptions about catastrophic forgetting in PLMs. While the proposed method (SEQ*) is simple, the insight that 'forgetting is in the head, not the body' is a significant conceptual correction for the field.