📝 Paper Summary
LLM Alignment
Synthetic Data Generation
SPIN iteratively fine-tunes a language model by having it play against itself, generating synthetic data and learning to distinguish its own previous responses from human-annotated ground truth.
Core Problem
Standard Supervised Fine-Tuning (SFT) quickly reaches a performance plateau, and further alignment typically requires costly human feedback (RLHF) or GPT-4 preference data (DPO).
Why it matters:
- Acquiring high-quality human annotations or GPT-4 preference data is expensive and unscalable.
- Current methods like SFT cannot effectively utilize the model's own generation capabilities to self-improve beyond the initial demonstration data.
- There is a need to bridge the gap between weak and strong models without external expert supervision.
Concrete Example:
After standard SFT on the Ultrachat200k dataset, the model zephyr-7b-sft-full still generates responses distinguishable from human ground truth. Simply continuing SFT on the same data leads to overfitting or stagnation, rather than improvement.
Key Novelty
Self-Play fIne-tuNing (SPIN)
- Treats fine-tuning as a two-player game where the 'main player' (current model) tries to distinguish human data from the 'opponent' (previous model iteration) responses.
- The opponent generates synthetic responses to SFT prompts; the main player optimizes a loss function that widens the gap between the likelihood of human data and opponent data.
- Operates iteratively: the improved main player becomes the opponent for the next round, progressively aligning the model's distribution with the target data distribution.
Architecture

Pseudocode for the Self-Play fIne-tuNing (SPIN) algorithm.
Evaluation Highlights
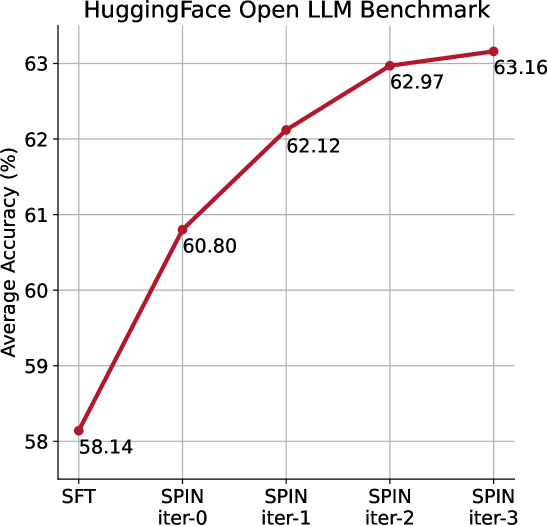
- Improves zephyr-7b-sft-full from 58.14 to 63.16 (+5.02) average score on the HuggingFace Open LLM Leaderboard, surpassing base SFT performance.
- Achieves a +10% improvement on GSM8k (math) and TruthfulQA benchmarks compared to the base SFT model.
- Increases MT-Bench score from 5.94 to 6.78, outperforming models trained with Direct Preference Optimization (DPO) on additional GPT-4 preference data.
Breakthrough Assessment
8/10
Offers a significant methodological shift by eliminating the need for external reward models or preference data (human or GPT-4) for alignment, achieving strong results purely through self-play.