📝 Paper Summary
Explainable Recommendation
Graph Neural Networks (GNNs)
Counterfactual Reasoning
CPER replaces unstable attention weights in path-based recommenders with counterfactual reasoning scores derived from perturbing both path embeddings and topological structures.
Core Problem
Attention weights in graph-based recommendations are often unstable across runs and biased toward frequent but uninformative paths, making them unreliable for explanation.
Why it matters:
- Users lose trust in recommendation systems when explanations (e.g., 'bought X because of Y') change randomly between identical runs
- Standard attention mechanisms fail to identify specific, informative paths, instead favoring generic, high-frequency connections that carry little semantic meaning
- Current counterfactual methods focus on items or user features, lacking support for the path-based reasoning critical for knowledge graph interpretability
Concrete Example:
In an Amazon Musical Instrument dataset, an attention model might highlight a generic path through the 'Musical Instrument' category node simply because it's a high-degree hub, ignoring a more specific, informative path (e.g., via a niche brand). Additionally, running the same model twice might yield completely different attention heatmaps for the same recommendation.
Key Novelty
Dual-perspective Counterfactual Path Reasoning
- Perturbs path embeddings mathematically to find the minimal vector change needed to flip a recommendation, using the magnitude of the result drop as the path's importance score
- Perturbs path structures topologically via a reinforcement learning agent that learns to swap nodes in paths, identifying which structural changes most degrade the recommendation
Architecture
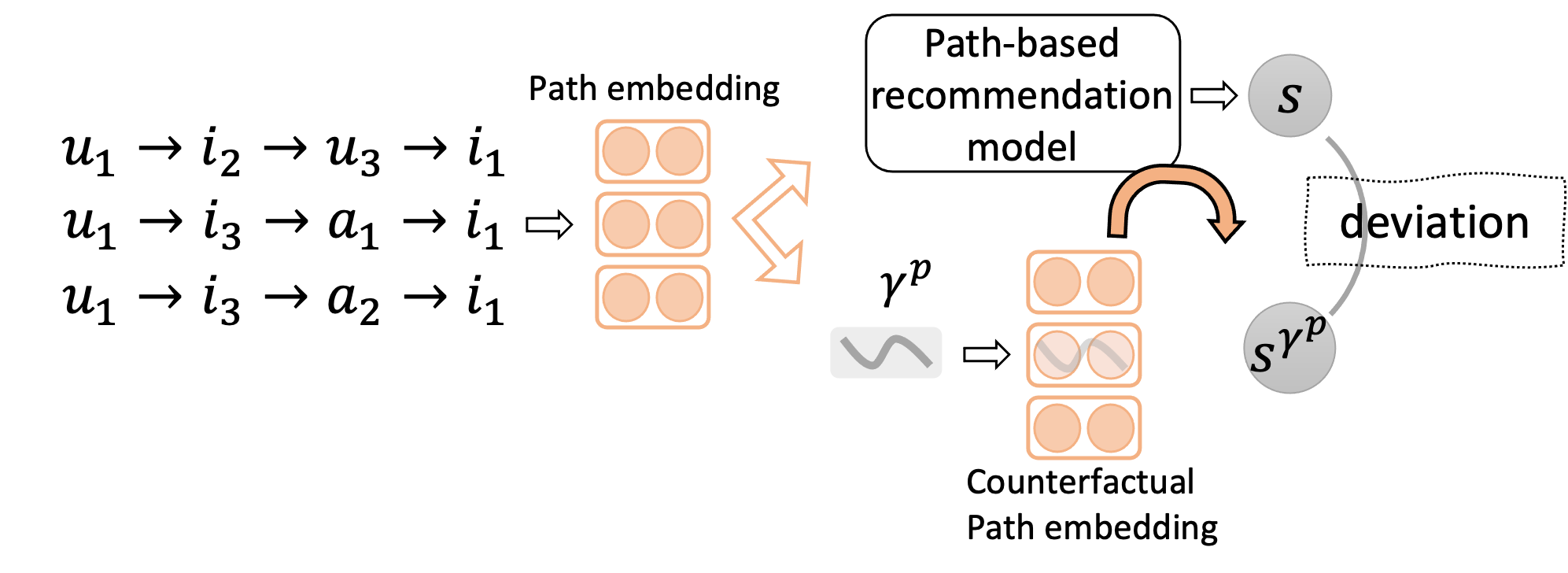
Illustration of Counterfactual Reasoning on Path Representations. It shows original paths being perturbed by a vector gamma to create counterfactual paths, which are fed into the recommender to measure score deviation.
Evaluation Highlights
- Achieves higher Fidelity (explanation faithfulness) compared to attention baselines, meaning removing CPER-identified paths causes a larger drop in recommendation scores
- Demonstrates superior Stability, producing consistent explanation weights across multiple independent training runs unlike attention mechanisms
- Identifies paths with higher Uncertainty (entropy), indicating it successfully avoids trivial, high-frequency paths in favor of more informative ones
Breakthrough Assessment
7/10
Solid methodological contribution applying counterfactuals to path-based GNN explanations. The dual approach (embedding + structure) is clever, though the evaluation relies heavily on relative metrics like fidelity rather than user studies.