📝 Paper Summary
Knowledge Base Question Answering (KBQA)
Semantic Parsing
LLM Evaluation
LLMs are highly proficient at understanding formal languages (translating them to natural language) but struggle significantly to generate them correctly, with performance heavily dependent on how similar the formal syntax is to natural language.
Core Problem
While LLMs are used for semantic parsing in KBQA, there is little understanding of their varying proficiency across different formal languages (KoPL, SPARQL, Lambda DCS) or their inherent ability to understand vs. generate these structures.
Why it matters:
- Current approaches blindly apply LLMs to semantic parsing without knowing which formal languages leverage LLM strengths best
- Understanding the 'generation gap' between understanding and producing code is crucial for designing reliable neuro-symbolic systems
- Selecting the wrong formal language target (e.g., one highly dissimilar to natural language) can bottleneck KBQA performance regardless of model size
Concrete Example:
When asked to generate a Lambda DCS logical form for 'Which cost less? Batman Begins released in Italy or Toostie', models like GPT-3.5 fail to produce valid code even with few-shot examples, achieving <5% accuracy, whereas they can easily translate the reverse direction (code to text).
Key Novelty
Bidirectional Proficiency Probing for KBQA Formalisms
- Evaluates LLMs on both 'Understanding' (Code-to-Text) and 'Generation' (Text-to-Code) across three distinct formal languages (KoPL, SPARQL, Lambda DCS) to reveal asymmetry in capabilities
- Proposes a 'Contrastive Evaluation' for understanding: instead of unreliable text metrics (BLEU), train a small parser on LLM-generated synthetic data and measure its KBQA accuracy against a parser trained on human data
- Introduces a structure-preserving retrieval strategy for In-Context Learning that selects demonstrations based on tree-edit distance of logical skeletons rather than just semantic similarity
Architecture
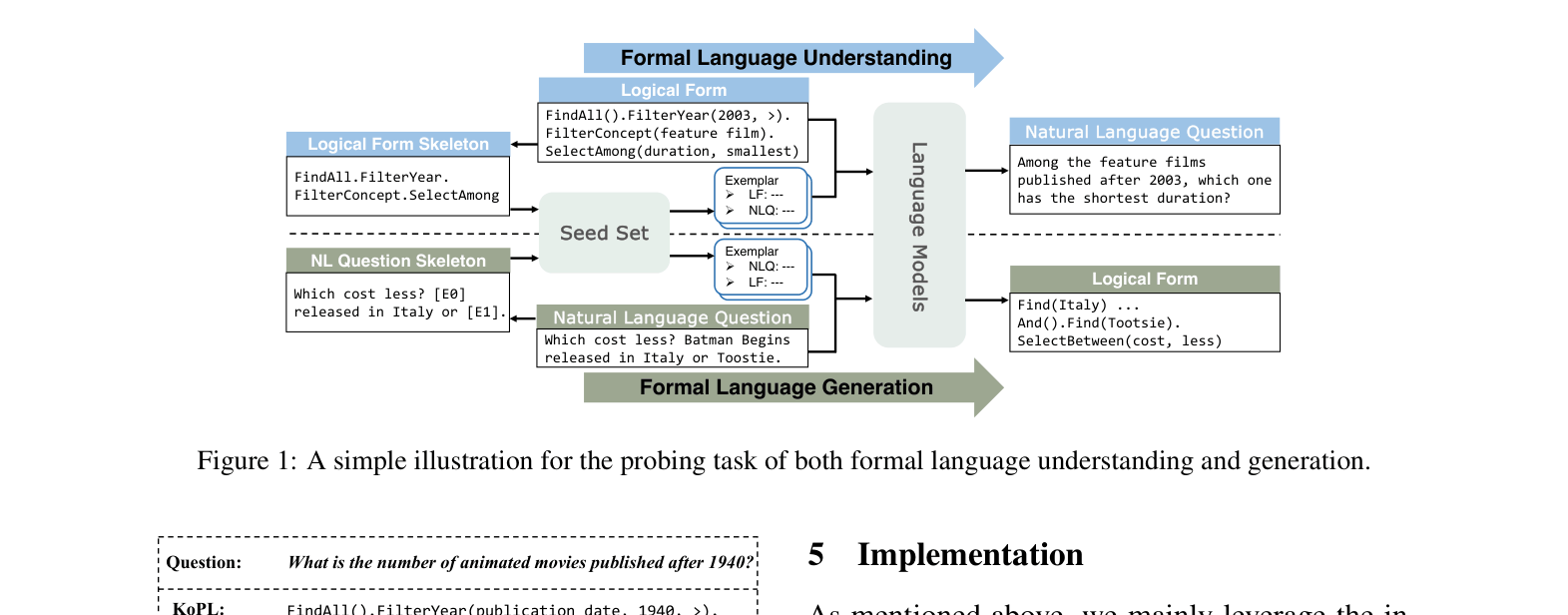
Illustration of the bidirectional probing tasks: Formal Language Understanding (translating LF to NLQ) and Formal Language Generation (translating NLQ to LF), showing inputs and retrieved exemplars.
Evaluation Highlights
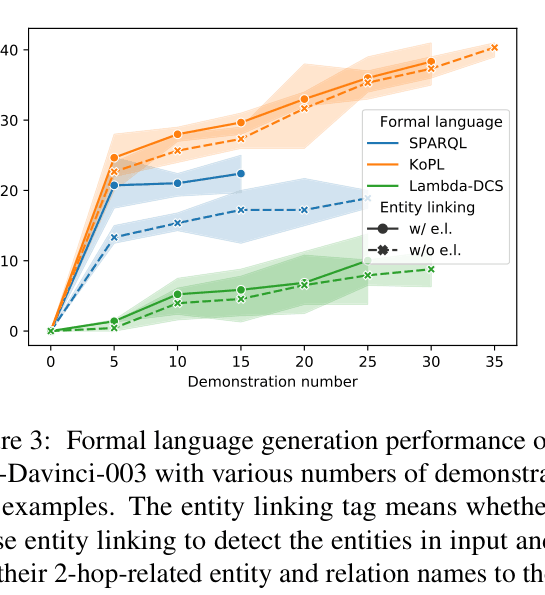
- Understanding Gap: Text-Davinci-003 achieves 88.1% accuracy on KoPL understanding (close to human's 90.6%), but only 41.6% on generation.
- Language Sensitivity: Models perform best on KoPL (most NL-like), achieving 41.6% generation accuracy, vs. 22.5% for SPARQL and 10.0% for Lambda DCS.
- Entity Linking Impact: Adding entity/relation candidates to the prompt boosts Text-Davinci-003's SPARQL generation from ~2% to 22.5%.
Breakthrough Assessment
7/10
Provides a valuable, rigorous diagnostic analysis of LLM limitations in semantic parsing. The finding that 'understanding >> generation' and the ranking of formal languages by NL-similarity are important practical insights for KBQA system design.