📝 Paper Summary
Scientific Reasoning
Instruction Tuning
Mathematical Reasoning
SciInstruct is a comprehensive instruction dataset constructed via a self-reflective agent pipeline to improve LLM performance on college-level scientific and mathematical reasoning tasks.
Core Problem
General LLMs struggle with intricate scientific concepts, symbolic equation derivation, and advanced numerical calculations required for college-level science problems.
Why it matters:
- Reliable scientific reasoning is a prerequisite for using LLM agents to accelerate scientific discovery (e.g., protein prediction, weather forecasting)
- Existing scientific data is scarce, often protected by IP, and lacks the detailed step-by-step reasoning traces (Chain-of-Thought) needed for effective training
- Training solely on Question-Answer pairs without reasoning steps leads to poor performance and can degrade general language capabilities
Concrete Example:
When asked to calculate energy using the Planck distribution, standard LLMs fail to identify the correct combination of physical concepts, deduce formal equations, or perform rigorous numerical computing, achieving only ~28% accuracy on some college-level textbooks.
Key Novelty
Self-Reflective Instruction Annotation Framework
- Uses a teacher LLM (GPT-4) to generate reasoning steps for unlabelled scientific questions, then autonomously critiques and revises its own outputs based on answer correctness
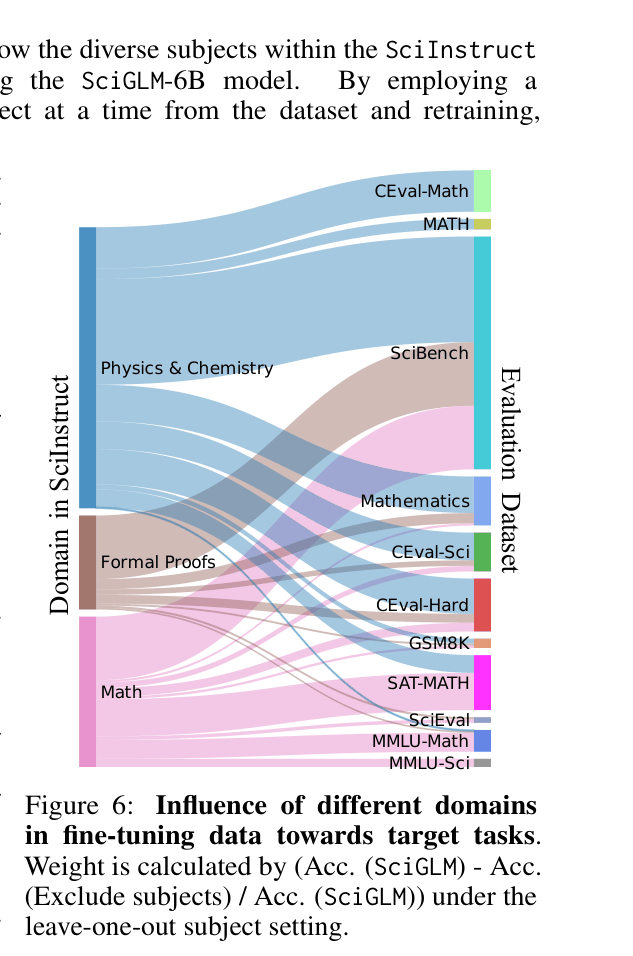
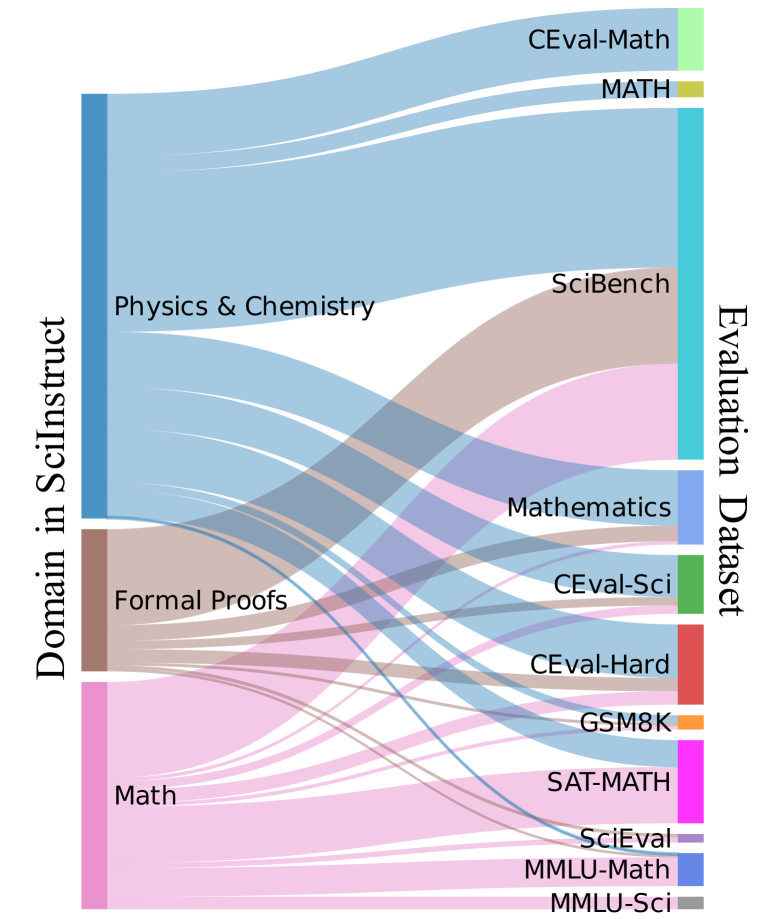
- incorporates a diverse mixture of data sources including physics/chemistry problems, math calculation data, and formal theorem proofs (Lean) to prevent overfitting to single subjects
- Employs an instruction-quality classifier trained on labeled data to filter out low-quality synthetic instructions before fine-tuning
Architecture
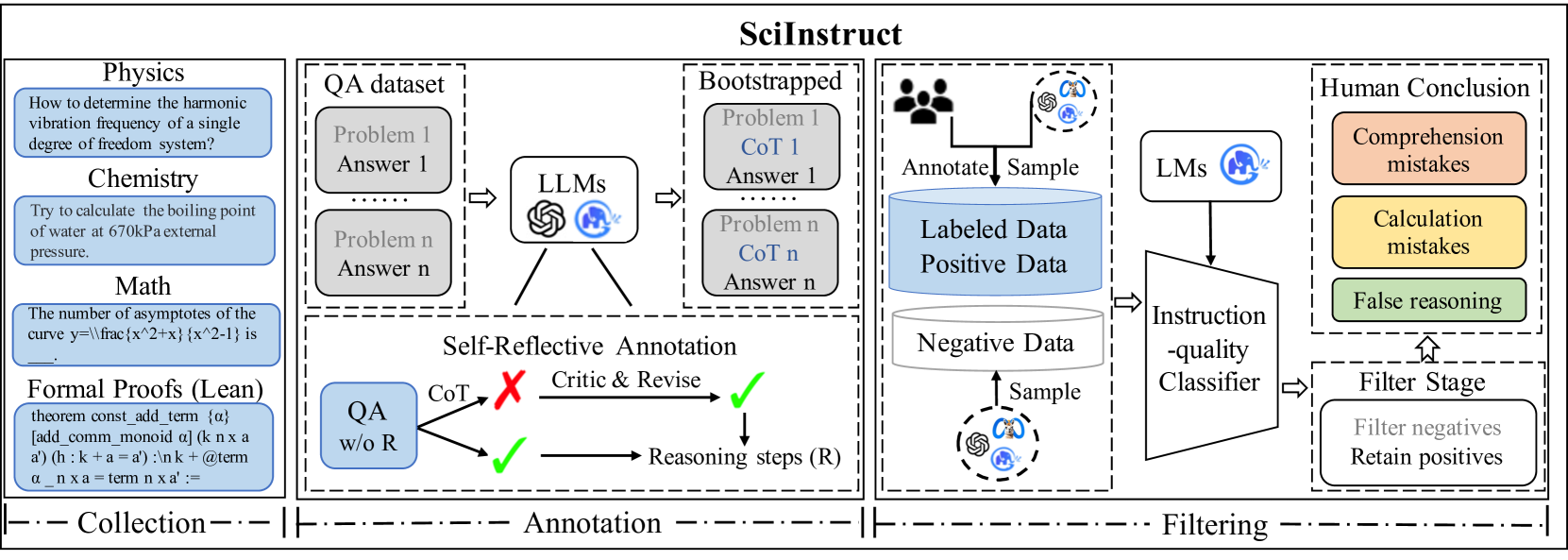
The overall pipeline for constructing SciInstruct, including data collection from diverse subjects, the self-reflective annotation process using LLMs, and the final filtering/tuning steps.
Evaluation Highlights
- +4.87% improvement in average scientific benchmark accuracy for SciGLM-6B compared to its base model (ChatGLM3-6B)
- Outperforms Galactica (120B) on scientific problems despite being a much smaller 6B/32B model
- Maintains general language understanding capabilities (slight improvement on MMLU/CEval) unlike models that catastrophic forget during domain specialization
Breakthrough Assessment
8/10
Significant contribution in addressing data scarcity for scientific reasoning via self-reflection. The resulting dataset and models show strong improvements without sacrificing general capability.