📝 Paper Summary
Hallucination detection
Hallucination editing / correction
Fava improves LM factuality by detecting and editing six distinct types of hallucinations using a retrieval-augmented model trained on carefully curated synthetic data.
Core Problem
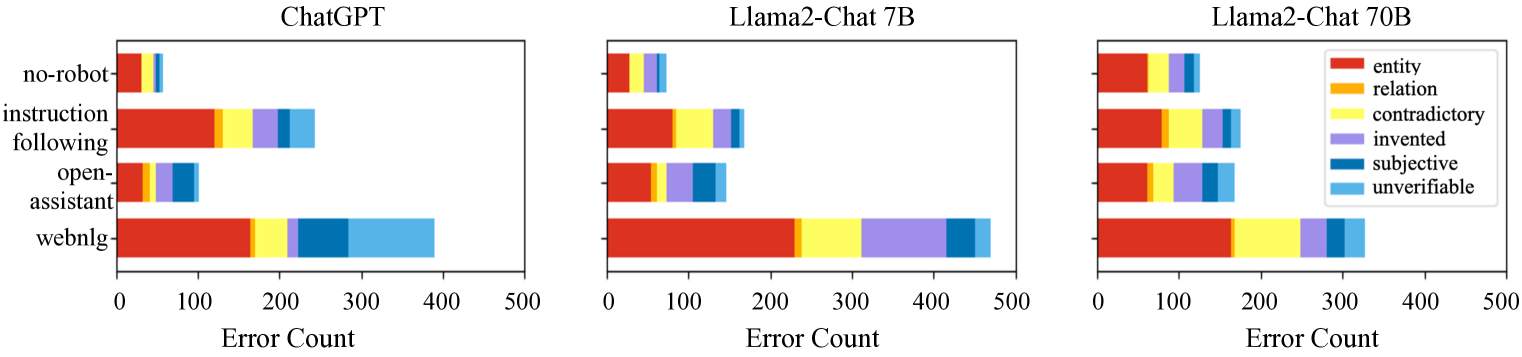
Existing hallucination detection systems rely on simplistic binary labels (factual vs. non-factual) or focus only on entities, ignoring diverse error types like unverifiable claims or subjective opinions.
Why it matters:
- Different hallucination types require different fix strategies (e.g., editing a specific entity vs. removing an entire unverifiable sentence)
- Over 60% of LM-generated hallucinations are non-entity errors (e.g., unverifiable sentences) which current entity-focused systems miss
- Deploying LMs in information-seeking contexts is dangerous without precise identification of fabricated or subjective content
Concrete Example:
A model might generate 'The Messi Diaries,' a non-existent book. A binary detector just says 'wrong,' but Fava identifies this as an 'Invented' error requiring removal, whereas a date error like 'born in 2000' is an 'Entity' error requiring a specific edit.
Key Novelty
Fava (FActVerification with Augmentation)
- Introduces a 6-category taxonomy for hallucinations (e.g., Entity, Relation, Invented, Subjective) rather than binary labels
- Uses a 'generate-and-edit' pipeline where a small LM is trained to detect specific error spans and rewrite them using retrieved evidence
- Creates synthetic training data by prompting GPT-4/ChatGPT to inject specific error types into clean text, simulating how LMs hallucinate
Architecture
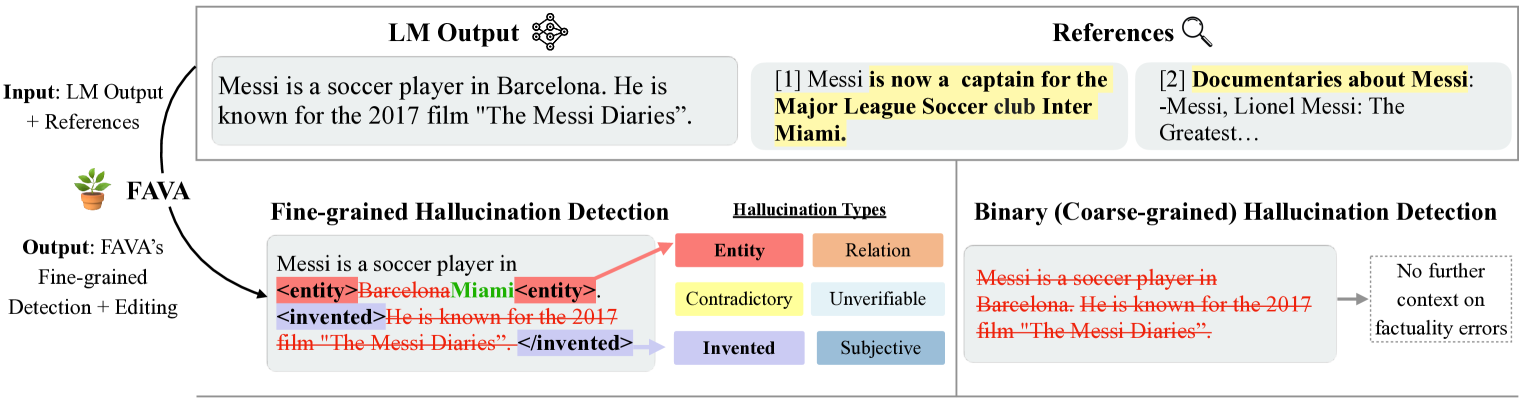
The Fava inference pipeline showing retrieval and generation with tags.
Evaluation Highlights
- Fava outperforms ChatGPT (with retrieval) by 23.7% on fine-grained hallucination detection accuracy
- Improves the factuality score (FActScore) of Alpaca 13B outputs by 9.3% through automated editing
- On binary detection, Fava outperforms the widely-used FActScore system and GPT-4 baselines
Breakthrough Assessment
8/10
Strong contribution with a necessary shift from binary to fine-grained detection. The taxonomy and synthetic data generation pipeline are highly practical for the field.