📝 Paper Summary
In-Context Learning (ICL)
Prompt Engineering
Demonstration Selection
In-Context Reflection (ICR) iteratively selects demonstrations that the LLM misclassifies with high confidence, providing the model with the exact 'lacking knowledge' needed to bridge the gap between its internal priors and the specific task.
Core Problem
In-Context Learning is highly sensitive to demonstration selection, but existing methods either rely on expensive external supervision (scorers) or computationally heavy influence analysis (repeated binary tests).
Why it matters:
- Poor demonstration selection can lead to significant performance drops in few-shot learning scenarios.
- Relying on external scorers (like BERT or reward models) assumes their preferences align with the LLM's in-context mechanism, which is not always true.
- Influence analysis requires querying the LLM for every candidate-test pair, making it unscalable for large pools.
Concrete Example:
If an LLM consistently misclassifies a specific type of sarcasm as 'neutral' with high confidence (high discrepancy), standard selection might miss this blind spot. ICR identifies these confident errors and explicitly adds them to the prompt to correct the model's boundary.
Key Novelty
In-Context Reflection (ICR)
- Identifies 'misconfidence': selecting examples where the model is confident but wrong, indicating a gap between the model's priors and the task truth.
- Iterative refinement: Starts with random shots, then replaces the least informative ones with high-misconfidence examples found using the current prompt.
- Efficient approximation: Uses the LLM's own probability distribution to measure discrepancy without needing external retrievers or thousands of influence trials.
Architecture
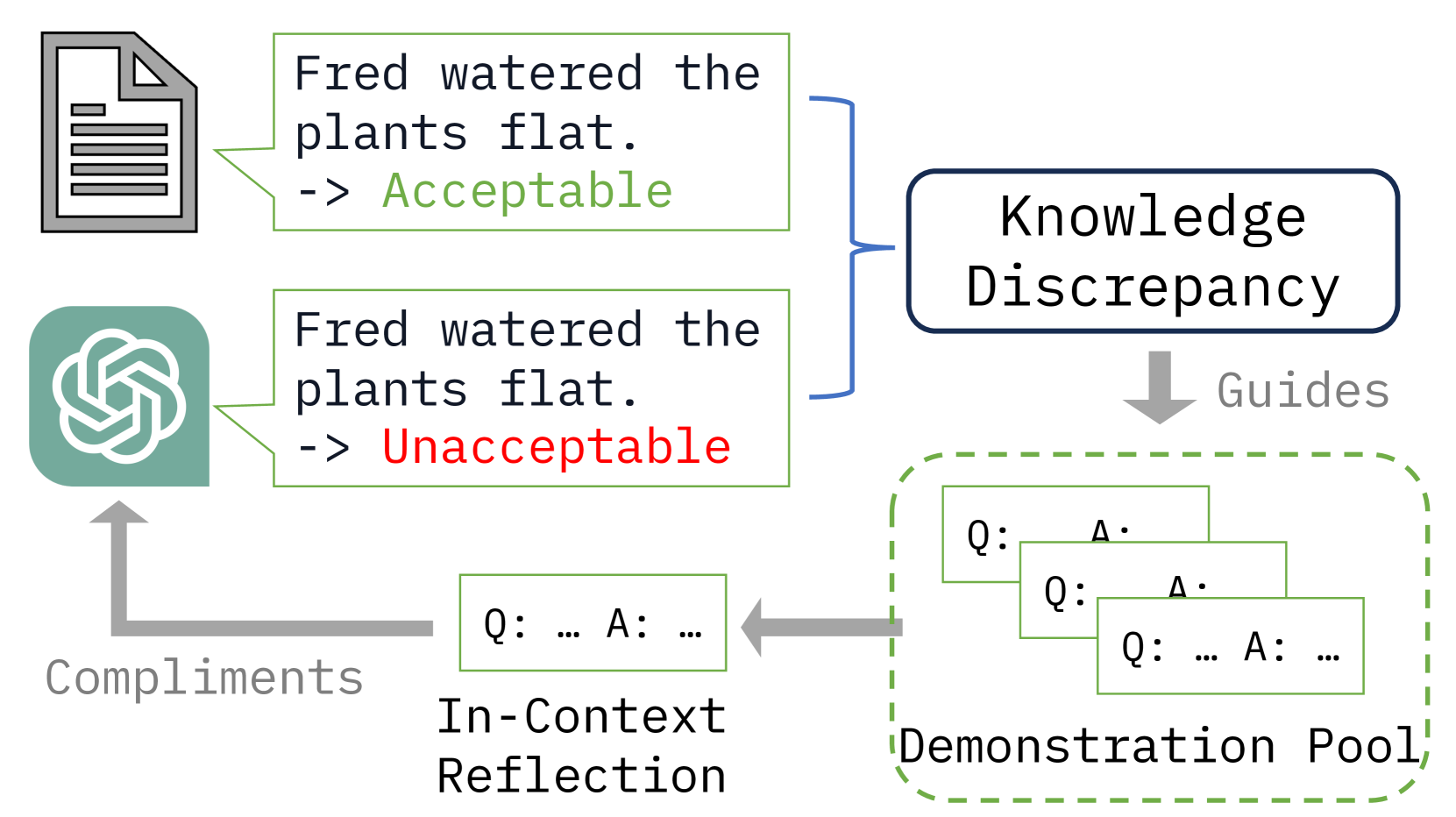
The iterative process of In-Context Reflection.
Evaluation Highlights
- Achieves an average performance boost of 4% across 13 diverse tasks (including GLUE and TweetEval) compared to existing methods.
- Outperforms semantic retrieval methods (KATE) and influence-based methods while requiring only one inference pass per training candidate.
- Demonstrates robustness in cross-task transfer: prompts generated for one task perform comparably to same-task uniform sampling when transferred to related tasks within the same family.
Breakthrough Assessment
7/10
Provides a mathematically grounded yet intuitive metric (misconfidence) that improves ICL significantly without external models. The 4% gain is substantial for this subfield.