📝 Paper Summary
Efficient Training
Progressive Training
Apollo accelerates deep model training by starting with a shallow network and progressively expanding it using a novel sampling strategy and interpolation method.
Core Problem
Training large Transformers from scratch is slow and resource-intensive, while existing progressive stacking methods often fail to achieve significant acceleration or suffer from instability.
Why it matters:
- Training large models consumes massive computational resources and time, leading to high financial and environmental costs.
- Relying on pretrained models limits applicability for new architectures where no prior weights exist.
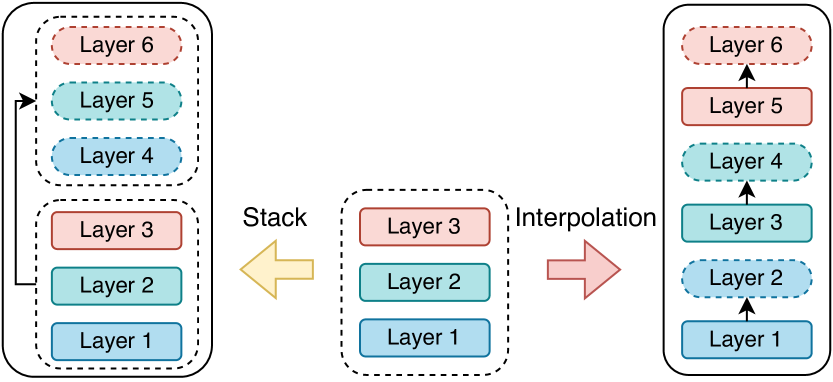
- Simple layer stacking (like StackBERT) is often unstable due to large gradients and semantic gaps between layers.
Concrete Example:
When training a 12-layer Transformer, StackBERT might copy the 6th layer's weights to initialize the 7th-12th layers. This abrupt change causes instability because the lower layers haven't learned high-level semantics, leading to slow convergence.
Key Novelty
Apollo (progressive expansion via weight sharing and interpolation)
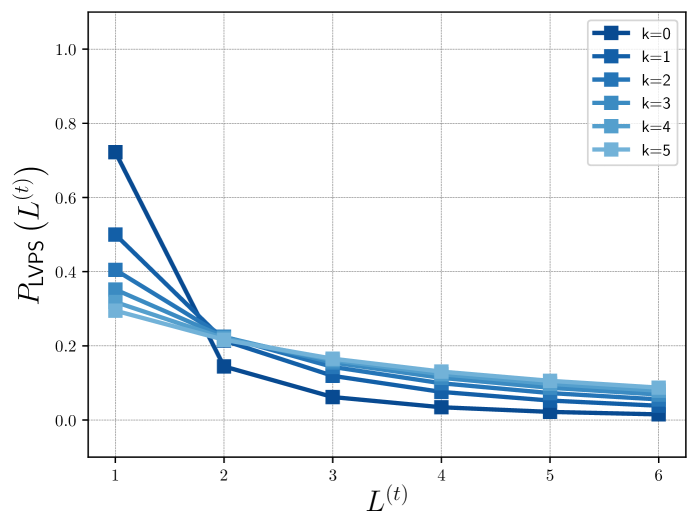
- Low-Value-Prioritized Sampling (LVPS): Randomly selects different network depths during early training, prioritizing shallow depths to save compute while exposing weights to high-level functional requirements.
- Weight Sharing: Uses shared weights across the sampled layers to learn features applicable to both low and high layers before expansion.
- Layer Interpolation: Expands the model depth by interpolating weights (mathematical blending) rather than direct stacking, ensuring smoother transitions and better stability.
Architecture
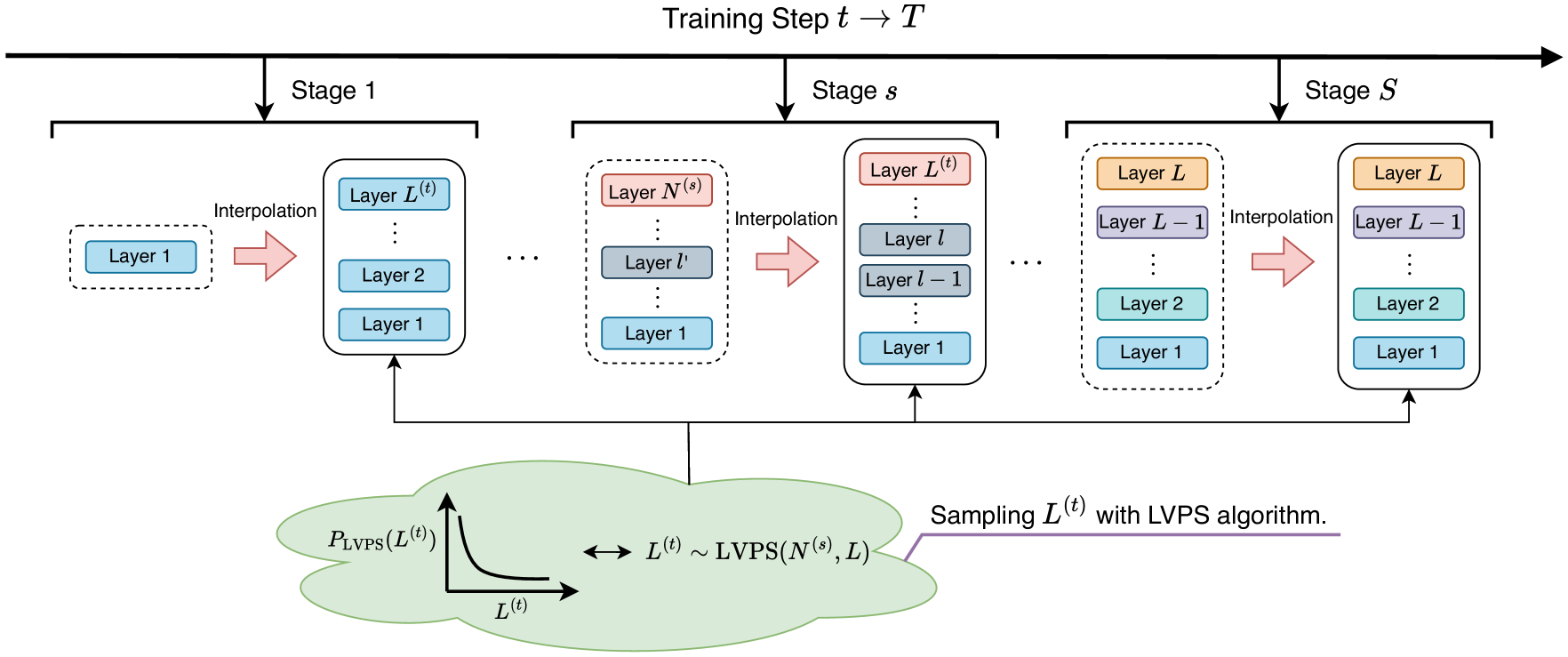
Conceptual illustration of Apollo's training process involving LVPS and expansion.
Evaluation Highlights
- Achieves state-of-the-art acceleration, outperforming StackBERT and even methods using pretrained models (like bert2BERT) in efficiency.
- Reduces training FLOPs substantially by sampling lower depths more frequently during the early stages via LVPS.
- Improves training stability compared to stacking methods, avoiding large gradient spikes during depth expansion.
Breakthrough Assessment
8/10
Offers a universal solution for efficient training from scratch that rivals pretrained initialization methods, addressing a critical bottleneck in training large custom architectures.