📝 Paper Summary
Time-Sensitive Question Answering (TSQA)
Hallucination Detection
Benchmarking
TDBench automates the creation of diverse time-sensitive QA pairs using temporal databases and SQL techniques to evaluate both answer accuracy and the validity of temporal reasoning in model explanations.
Core Problem
Existing Time-Sensitive Question Answering (TSQA) benchmarks rely on manual curation (costly, unscalable) or fixed templates (limited diversity), and often ignore whether the model's temporal reasoning explanation is actually correct.
Why it matters:
- Facts evolve over time (e.g., presidents change), making static knowledge insufficient for reliability
- LLMs frequently hallucinate explanations even when getting the final answer right, undermining trust
- Current evaluation methods struggle to support application-specific data or complex multi-hop reasoning without heavy human labor
Concrete Example:
A model correctly answers 'Carl XVI Gustaf' is the current monarch of Sweden but explains he has been monarch 'since 1974' (hallucinated date), which standard answer-only metrics fail to detect.
Key Novelty
Database-Driven TSQA Benchmark Construction
- Uses Temporal Functional Dependencies (TFDs) to automatically identify facts that are uniquely determined by time (e.g., Country + Role → Name)
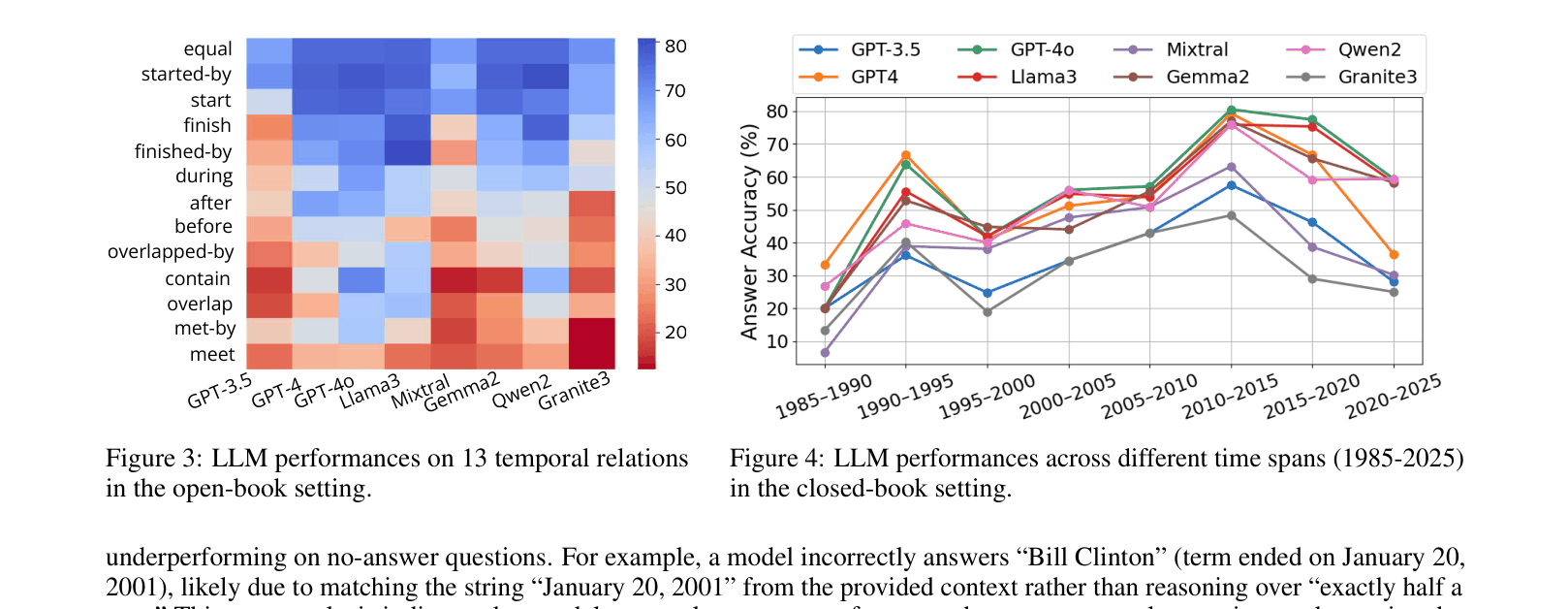
- Generates questions via temporal SQL queries covering 13 exhaustive temporal relations (e.g., 'meet', 'overlap', 'during') rather than hand-written templates
- Evaluates 'Time Accuracy' by checking if the specific dates mentioned in the model's explanation satisfy the temporal constraints defined in the generated SQL
Architecture
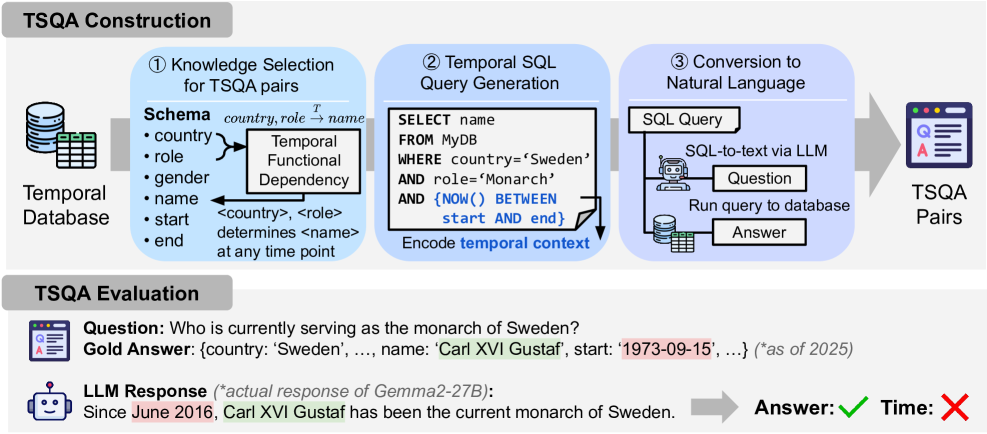
The three-step pipeline of TDBench: (1) Knowledge Selection using TFDs, (2) Query Generation creating Temporal SQL, and (3) QA Construction converting SQL to Natural Language.
Evaluation Highlights
- Detected hallucinations in explanations for 21.7% of correctly answered questions on average across 8 LLMs
- Achieved 91.1% agreement with human verification for the automated time accuracy metric
- Identified that LLMs struggle significantly more with complex temporal relations like 'overlap' and 'meet' compared to simple ones like 'equal'
Breakthrough Assessment
8/10
Significantly advances TSQA by automating diverse question generation and introducing a reliable metric for verifying temporal reasoning, addressing a major blind spot in current answer-only evaluations.