📊 Experiments & Results
Evaluation Setup
Controlled switching evaluation where user prompt is fixed and alignment instruction varies.
Benchmarks:
- ECLIPTICA (Multi-way instruction switching (10 modes)) [New]
- TruthfulQA (Epistemic calibration switching)
- Conditional Safety (Policy-boundary switching (refusal vs. compliance))
- Length Control (Verbosity contract switching)
- LITMUS (Alignment Quality Index (AQI))
Metrics:
- Instruction-alignment efficiency (%)
- Delta (Instruct - NoInstruct)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of CITA against baselines on instruction-alignment efficiency across benchmarks. | ||||
| Average (5 benchmarks) | Instruction-alignment efficiency | 56.1 | 86.7 | +30.6 |
| Average (5 benchmarks) | Instruction-alignment efficiency | 36.1 | 86.7 | +50.6 |
| Average (5 benchmarks) | Instruction-alignment efficiency | 20.4 | 86.7 | +66.3 |
| Specific benchmark performance highlighting structural and calibration improvements. | ||||
| TruthfulQA | Adaptation Delta | 0.001 | 0.054 | +0.053 |
| Length Control | Adaptation Delta | 0.130 | 0.164 | +0.034 |
| LITMUS (AQI) | Adaptation Delta | -6.2 | 26.4 | +32.6 |
Experiment Figures
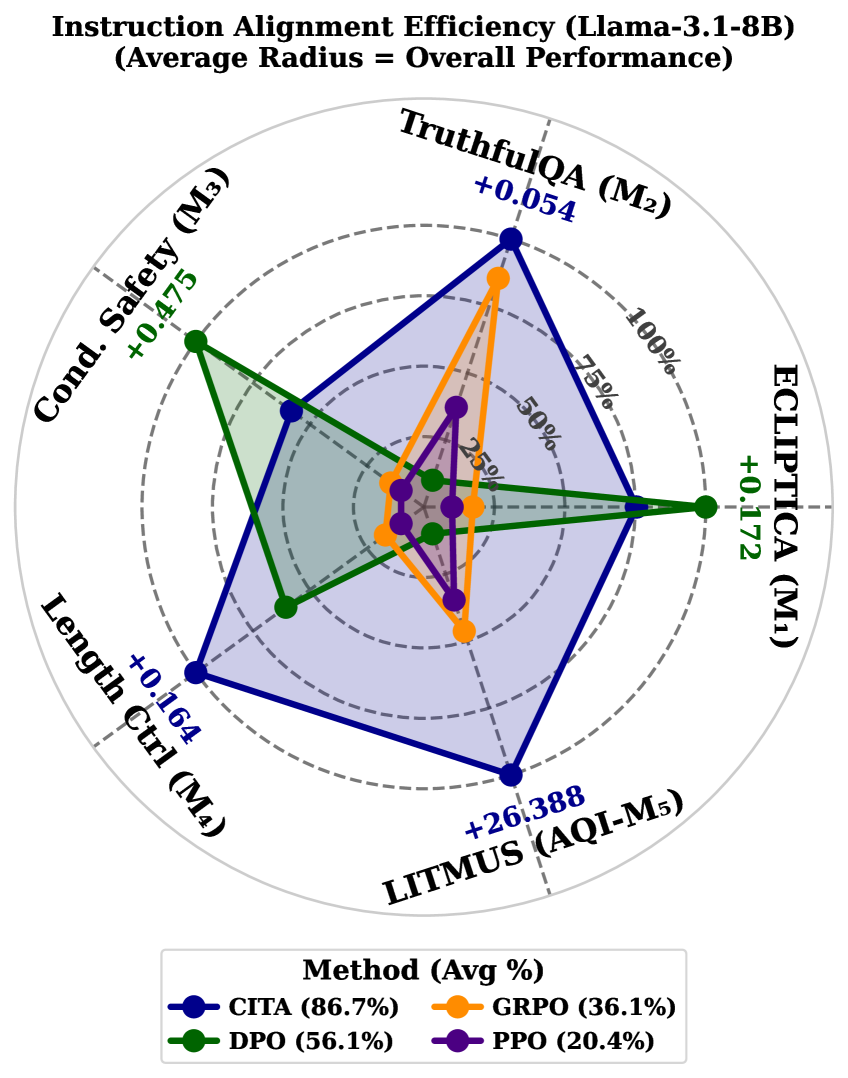
Aggregate performance comparison of CITA vs. DPO, GRPO, PPO across 5 benchmarks.
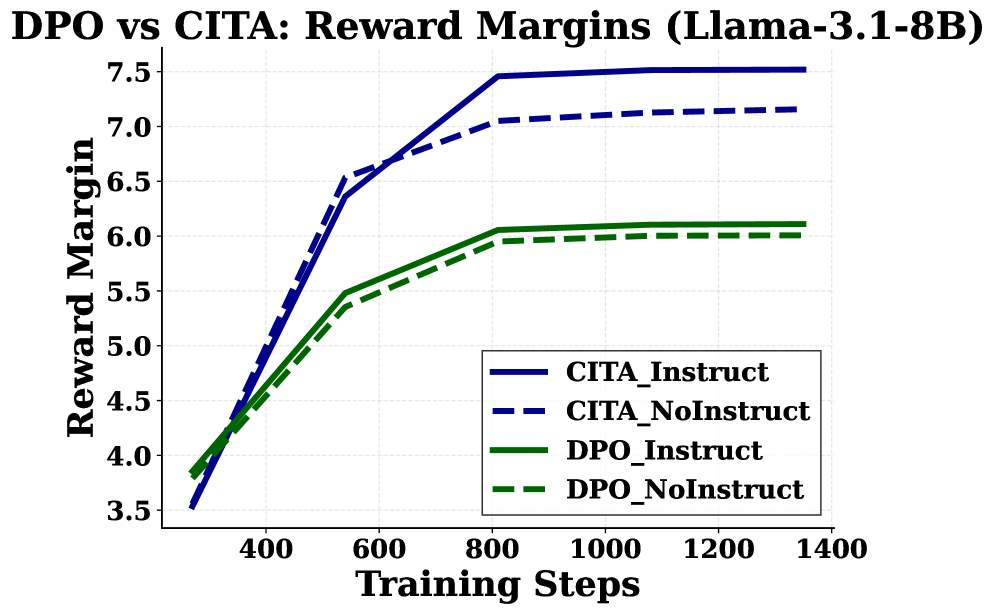
Reward margin curves during training.
Main Takeaways
- Instruction-Alignment is distinct from Instruction-Following; DPO may follow instructions but lacks stable switching on calibration and structure.
- CITA's mandatory KL anchor is structural, preventing mode collapse and enabling stable switching between neighboring optima.
- DPO performs well on binary safety switching (Conditional Safety) but struggles with continuous regime properties like calibration and length control compared to CITA.