📝 Paper Summary
Multilingual Language Modeling
Sparse Expert Models
Modular Deep Learning
x-elm mitigates parameter competition in multilingual models by independently training expert language models on subsets of data clustered by linguistic typology, allowing efficient scaling and adaptation without catastrophic forgetting.
Core Problem
Dense multilingual models force many languages to compete for fixed capacity (the 'curse of multilinguality'), causing performance degradation on individual languages compared to monolingual baselines.
Why it matters:
- Low-resource languages often suffer disproportionately when squeezed into a shared model with high-resource languages
- Training massive dense models requires synchronous high-end hardware clusters, limiting accessibility
- Adapting dense models to new languages risks catastrophic forgetting of previously learned languages
Concrete Example:
A dense model trained on 100 languages must share its weights across English, Swahili, and Vietnamese. As a result, its Swahili performance lags behind a dedicated Swahili model because the dense model's capacity is diluted by English and other languages.
Key Novelty
Cross-lingual Branch-Train-Merge (x-BTM) with Typological Experts
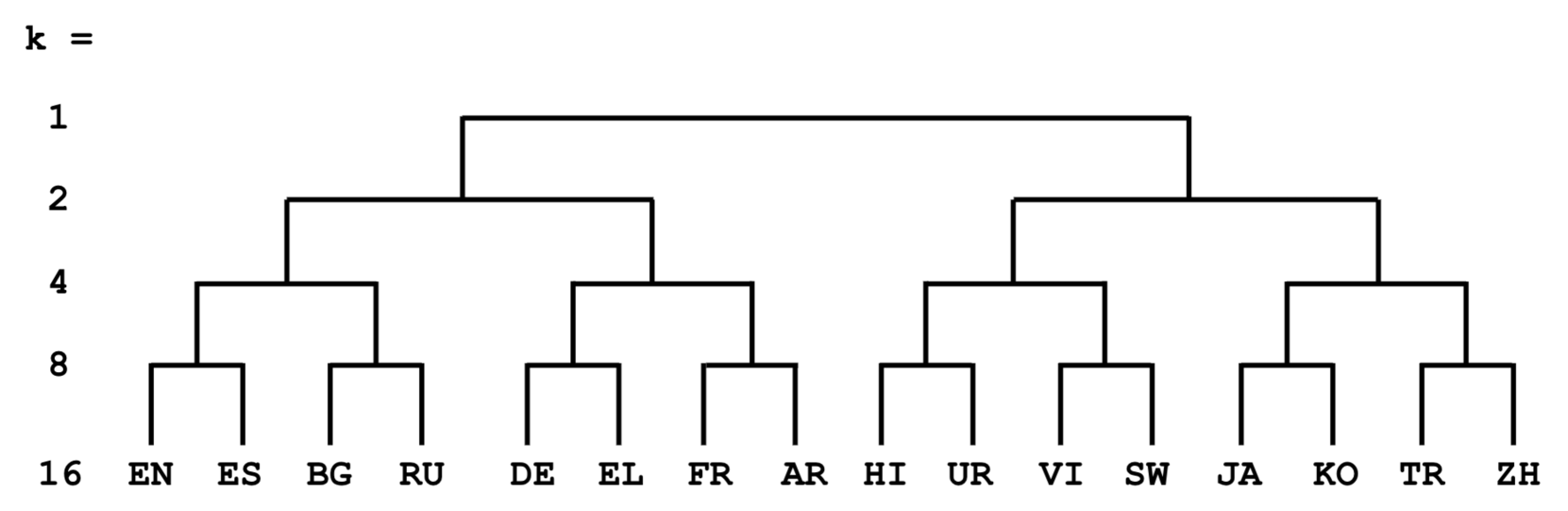
- Instead of one giant model, train separate 'expert' models initialized from a shared base, each specialized on a specific cluster of languages defined by linguistic typology (language family trees)
- Use 'Hierarchical Multi-Round' (HMR) training to adapt to new languages by branching off the most linguistically similar existing expert (e.g., seeding a Swedish expert from a Germanic-language parent expert) rather than retraining from scratch
Architecture
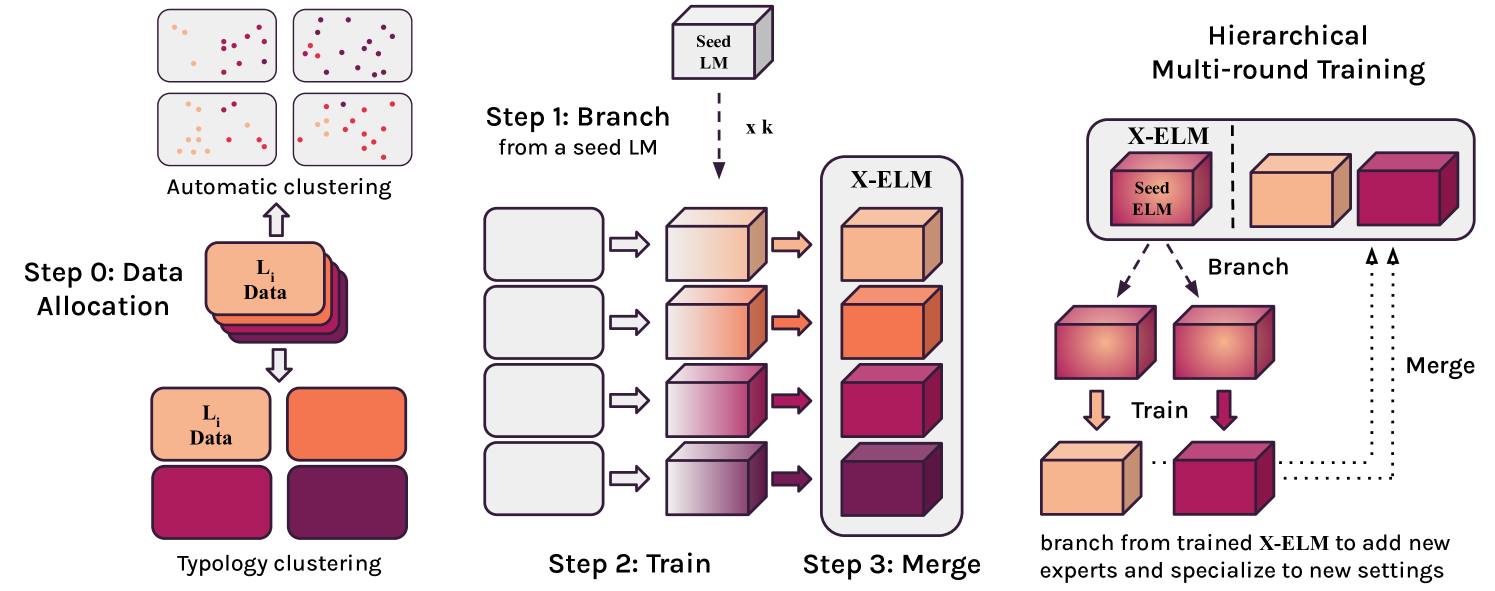
Conceptual diagram of x-elm training and Hierarchical Multi-Round (HMR) adaptation.
Evaluation Highlights
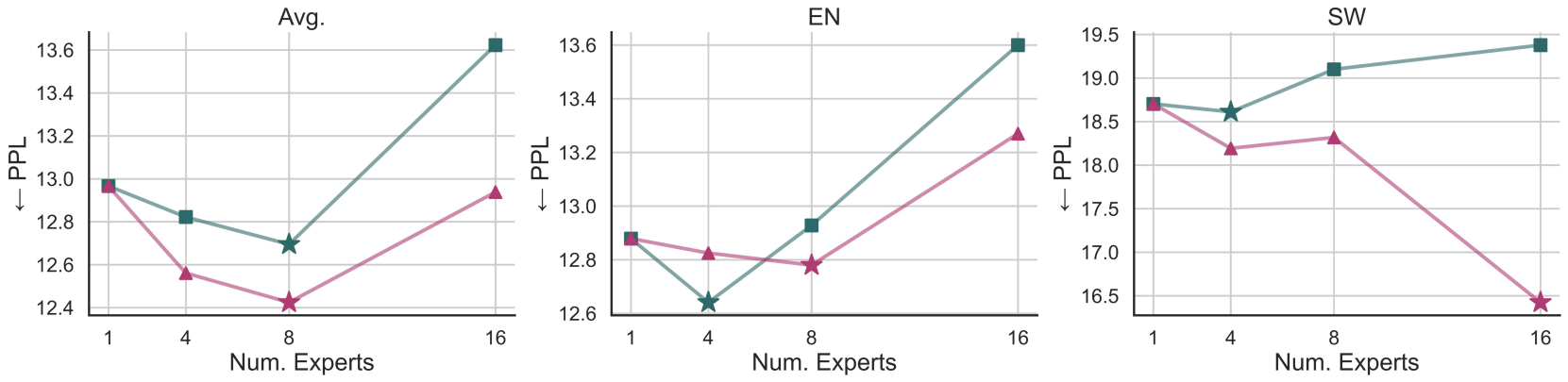
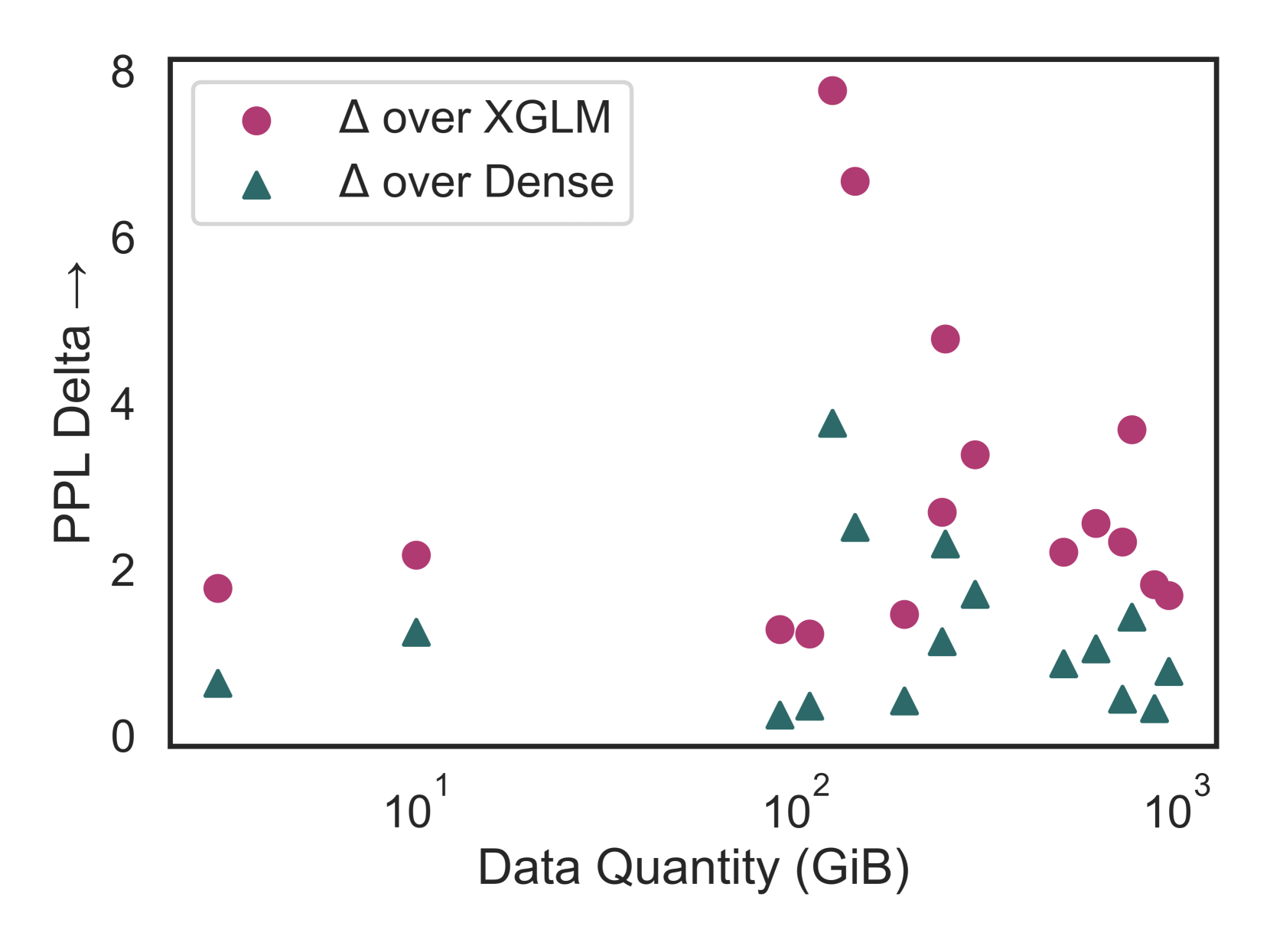
- Outperforms dense baselines on all 16 considered languages given the same compute budget (10.5B tokens), with perplexity reductions up to 7.77 points
- Hierarchical Multi-Round (HMR) adaptation to unseen languages (e.g., Azerbaijani, Hebrew) outperforms standard dense continued pretraining on every target language
- Typology-based clustering consistently outperforms data-driven TF-IDF clustering for assigning languages to experts
Breakthrough Assessment
8/10
Strong empirical evidence that sparse, linguistically-informed experts beat dense models for multilinguality. The HMR adaptation strategy offers a practical solution to the 'adding a language' problem without forgetting.