📝 Paper Summary
Sequential Recommendation
Cross-domain Recommendation
Zero-shot Learning
PrepRec learns universal item representations based purely on popularity dynamics (long-term and short-term trends) rather than item IDs or metadata, enabling zero-shot sequential recommendation across entirely different domains.
Core Problem
Sequential recommenders typically require training from scratch for each domain or rely on domain-specific auxiliary information (metadata) for transfer, preventing zero-shot application across diverse domains (e.g., grocery to movies) where metadata or IDs do not overlap.
Why it matters:
- Training domain-specific models is resource-consuming.
- Cross-domain transfer usually fails without shared IDs or compatible metadata (e.g., language mismatch).
- Cold-start or zero-shot scenarios need a universal mechanism to understand sequence patterns without relying on specific item content.
Key Novelty
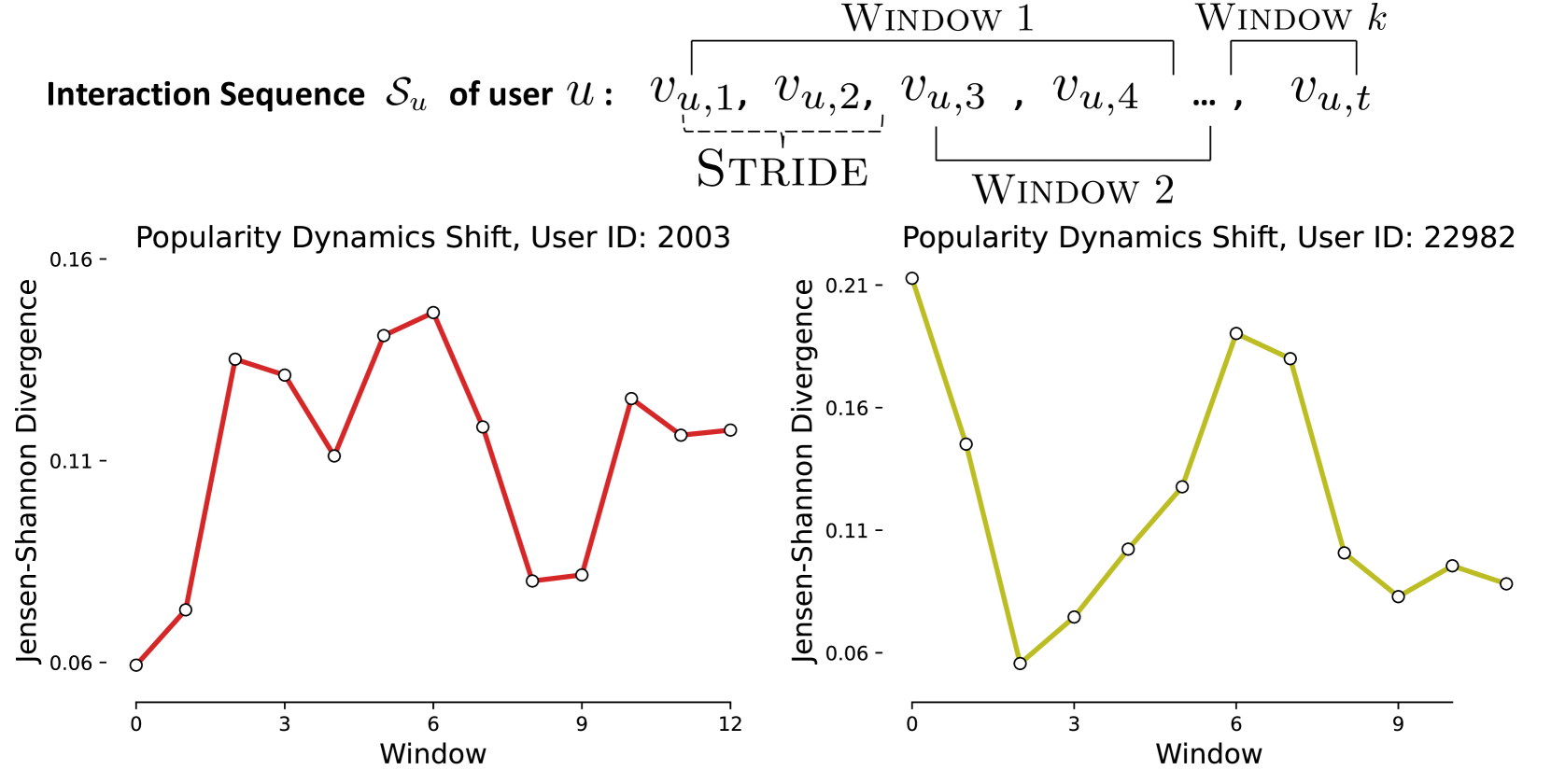
Popularity Dynamics-Aware Transformer for Universal Representation
- Items are represented not by IDs but by their popularity percentiles over coarse (long-term) and fine (short-term) time horizons.
- A linear encoding maps these popularity percentiles to dense vectors.
- The model uses relative time encoding and positional encoding within a Transformer architecture to capture sequential patterns of popularity shifts.
Architecture
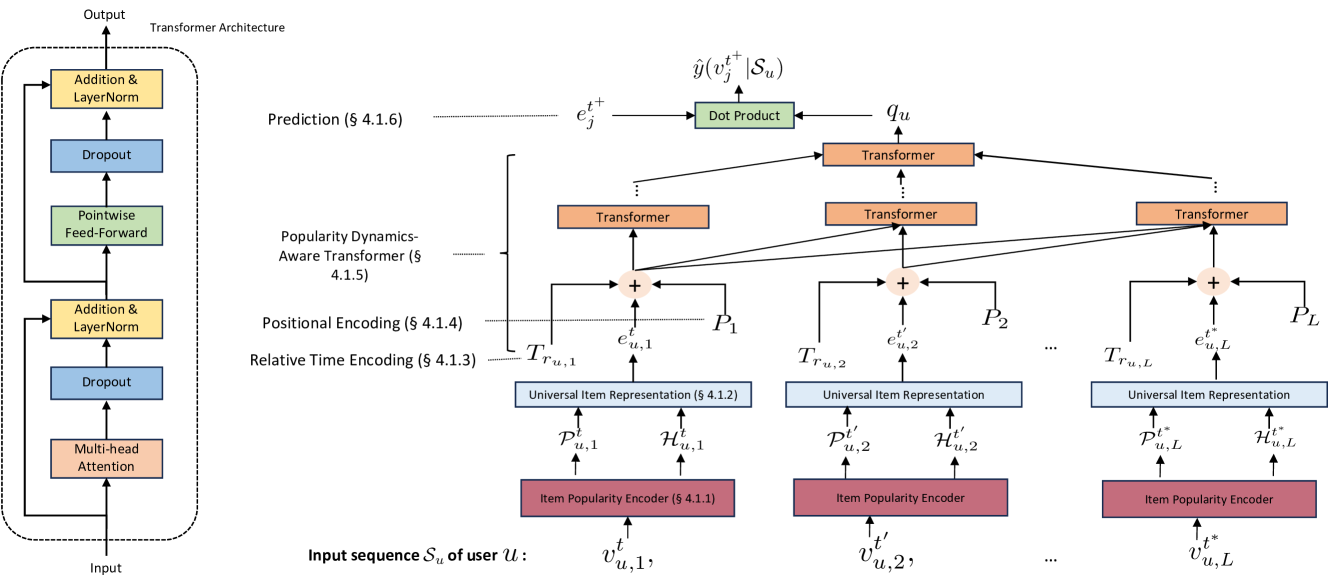
The PrepRec architecture showing inputs (percentile popularities), the encoding layer, relative time/positional encodings, and the Transformer stack.
Evaluation Highlights
- Zero-shot transfer: PrepRec trained on 'Office' and tested on 'Movie' achieves R@10 of 0.838, close to a fully trained BERT4Rec on 'Movie' (0.900).
- Zero-shot transfer: PrepRec trained on 'Movie' and tested on 'Music' achieves R@10 of 0.811, outperforming a fully trained BERT4Rec on 'Music' (0.782).
- Model size: PrepRec has significantly fewer parameters (~0.045M) compared to baselines like BERT4Rec (~2-7M) because it doesn't store item embedding tables.
- Interpolation: Combining PrepRec predictions with standard sequential models (BERT4Rec) yields large gains (e.g., +34.9% N@10 on 'Office', +20.3% R@10 on 'Movie'), showing it captures complementary signals.
Breakthrough Assessment
8/10
It introduces a radical shift by discarding item IDs entirely for transfer, proving that popularity dynamics alone contain sufficient signal for strong sequential recommendation performance, even outperforming trained baselines in some zero-shot settings.