📝 Paper Summary
Modularized RAG pipeline
Robustness in RAG
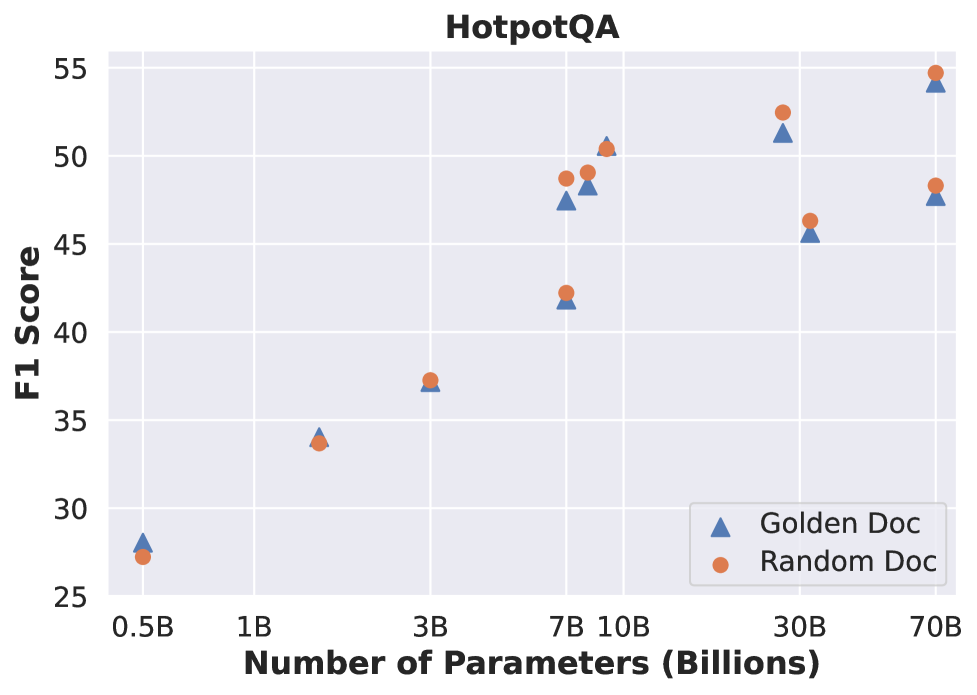
Sophisticated robust training methods for RAG systems become increasingly unnecessary as language models scale up, with simple strategies like random document selection performing comparably well on larger models.
Core Problem
RAG systems suffer when retrievers return noisy or irrelevant documents, prompting complex robust training methods (like adversarial selection) that may be computationally expensive and unnecessary for stronger models.
Why it matters:
- Current robust training methods (e.g., adversarial loss, careful document selection) require significant engineering effort and compute.
- It is unclear if these complex interventions remain effective or necessary as foundation models (like Llama-3 or Qwen2.5) become inherently more capable.
- Poor retrieval is a persistent bottleneck in RAG, leading to hallucinations if the generator cannot distinguish relevant from irrelevant context.
Concrete Example:
A base Llama-2-7b model drops to 3.3% Exact Match on HotpotQA when fed noisy documents. To fix this, researchers typically use complex adversarial training (RAAT). However, this paper asks if a stronger model (Llama-3) needs RAAT or if it can handle the noise naturally.
Key Novelty
The Law of Diminishing Returns for Robust RAG Training
- Empirically demonstrates that the performance gap between sophisticated robust training (e.g., adversarial loss) and simple baselines (e.g., random documents) shrinks drastically as model size increases.
- Identifies that larger models naturally possess better confidence calibration and attention patterns, allowing them to ignore irrelevant context without specialized training objectives.
Architecture
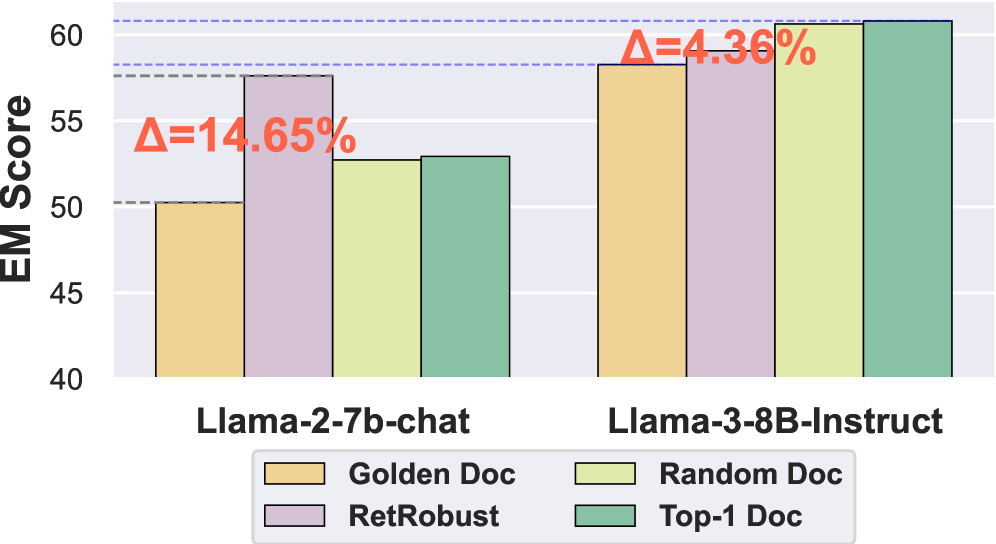
Preliminary analysis on TriviaQA comparing four training strategies across model scales.
Evaluation Highlights
- On WebQuestions, the performance gap between best and worst training strategies drops from 59.60% (Llama-2) to 16.94% (Llama-3).
- On the RAGuard benchmark with conflicting evidence, Llama-3-8B shows only a 1.92% gap between best and worst methods, compared to 21.45% for Llama-2-7b.
- Training larger models with random documents often matches or exceeds the performance of complex methods like RAAT or IRM.
Breakthrough Assessment
7/10
Strong empirical finding that challenges the prevailing trend of developing increasingly complex robust RAG training methods. Suggests a pivot in RAG design philosophy for large models.