📝 Paper Summary
Modularized RAG pipeline
Factuality
CRAG improves RAG robustness by using a lightweight evaluator to assess retrieved document quality and triggering different actions (Correct, Incorrect, Ambiguous) to refine, discard, or supplement information via web search.
Core Problem
Standard RAG systems indiscriminately incorporate retrieved documents regardless of relevance, causing hallucinations when retrieval fails or returns inaccurate results.
Why it matters:
- Low-quality retrievers introduce irrelevant information that impedes models from acquiring accurate knowledge
- Models can be misled by inaccurate retrieved documents, resulting in factual errors and hallucinations
- A considerable portion of text within retrieved documents is often non-essential for generation and should not be equally referred to
Concrete Example:
If a user asks 'Who is the CEO of Company X?' and the retriever returns an outdated document about a former CEO, a standard RAG model will likely hallucinate the wrong answer based on that irrelevant context. CRAG would detect the low relevance and trigger a web search for current information.
Key Novelty
Corrective Retrieval-Augmented Generation (CRAG)
- Retrieval Evaluator: A lightweight model (T5-Large) that assesses the quality of retrieved documents and assigns a confidence score
- Action Trigger: Determines whether to trust the documents (Correct), discard them and use web search (Incorrect), or combine both sources (Ambiguous) based on confidence thresholds
- Knowledge Refinement: A decompose-then-recompose algorithm that filters out irrelevant strips of information within valid documents to focus only on key insights
Architecture
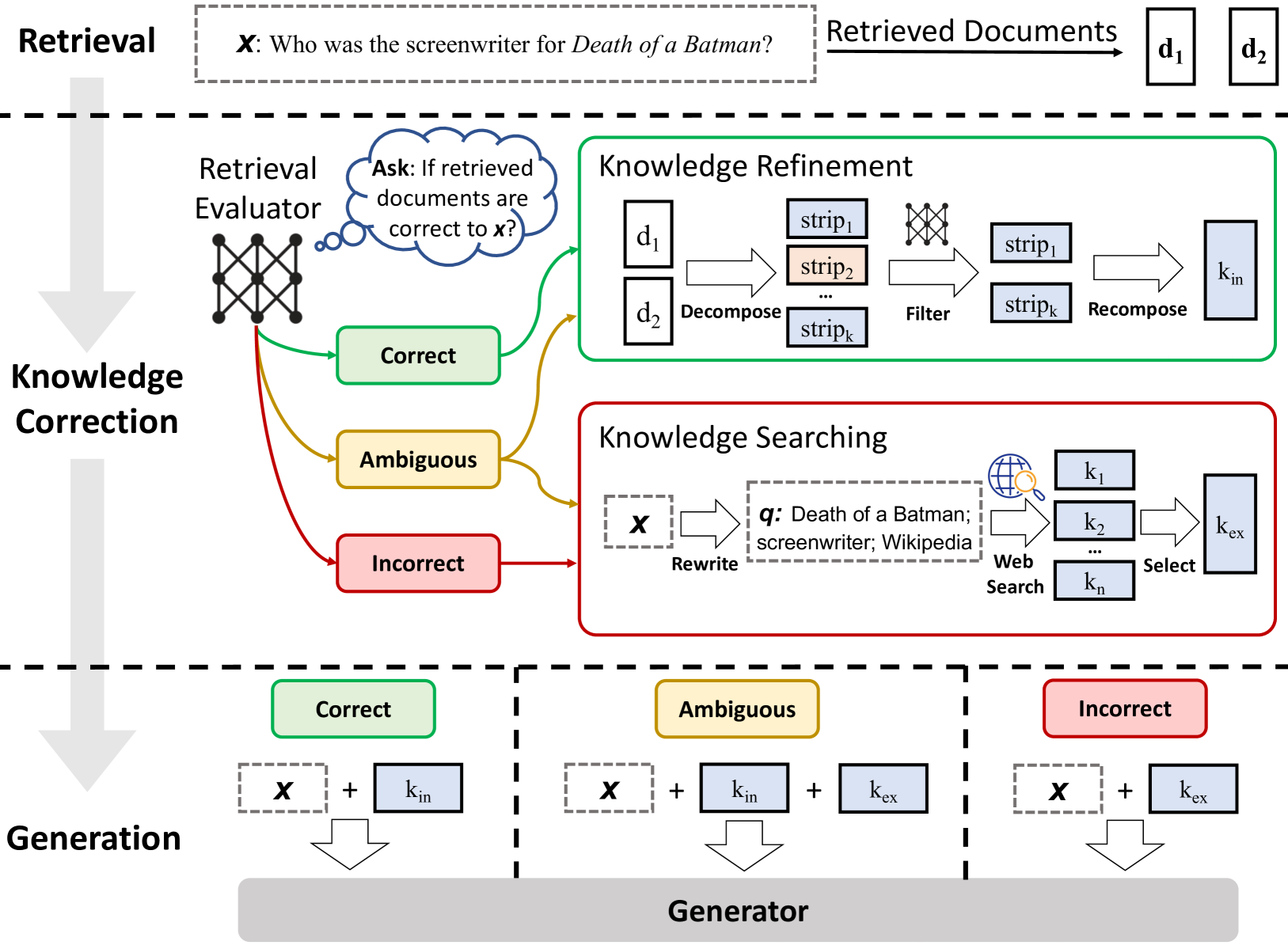
Overview of the CRAG inference process.
Evaluation Highlights
- Outperforms standard RAG by 15.4% accuracy on Arc-Challenge and 36.6% accuracy on PubHealth when using SelfRAG-LLaMA2-7b generator
- Improves state-of-the-art Self-RAG by 20.0% accuracy on PopQA and 36.9% FactScore on Biography when using LLaMA2-hf-7b generator
- Demonstrates generalization across short-form (PopQA) and long-form (Biography) generation tasks with consistent gains
Breakthrough Assessment
8/10
Significant improvement in RAG robustness by explicitly addressing retrieval failures. The plug-and-play nature and the introduction of 'corrective' actions (like web search fallback) are highly practical contributions.