📝 Paper Summary
Modularized RAG pipeline
MultiHop-RAG is a new benchmarking dataset specifically designed to evaluate RAG systems on complex multi-hop queries that require retrieving and reasoning over multiple distinct evidence documents.
Core Problem
Existing RAG benchmarks (like RGB and RECALL) primarily evaluate simple single-hop queries where answers reside in a single document, failing to assess capabilities on complex queries requiring multi-document reasoning.
Why it matters:
- Real-world queries often require connecting diverse information sources (e.g., comparing financial reports from two different years)
- Current benchmarks do not expose failures in multi-hop retrieval or reasoning, potentially overestimating system performance
- Standard similarity matching (cosine similarity) struggles when a query's answer depends on synthesizing disparate pieces of evidence rather than matching a single text chunk
Concrete Example:
A financial analyst asks: 'Which company among Google, Apple, and Nvidia reported the largest profit margins in 2023?' A standard RAG system might retrieve a single document about one company's margin but fail to retrieve and compare all three necessary reports to answer correctly.
Key Novelty
Multi-Hop RAG Benchmark Construction via Generator-Validator Pipeline
- Constructs a dataset specifically for multi-hop queries using real-world news articles as a knowledge base, unlike previous benchmarks focused on single-document retrieval
- Uses a semi-automated pipeline where GPT-4 paraphrases factual evidence into 'claims', extracts 'bridge-entities' (shared topics), and generates questions that require linking these separate claims
- Introduces four specific query types (Inference, Comparison, Temporal, Null) to test different reasoning capabilities beyond simple fact retrieval
Architecture
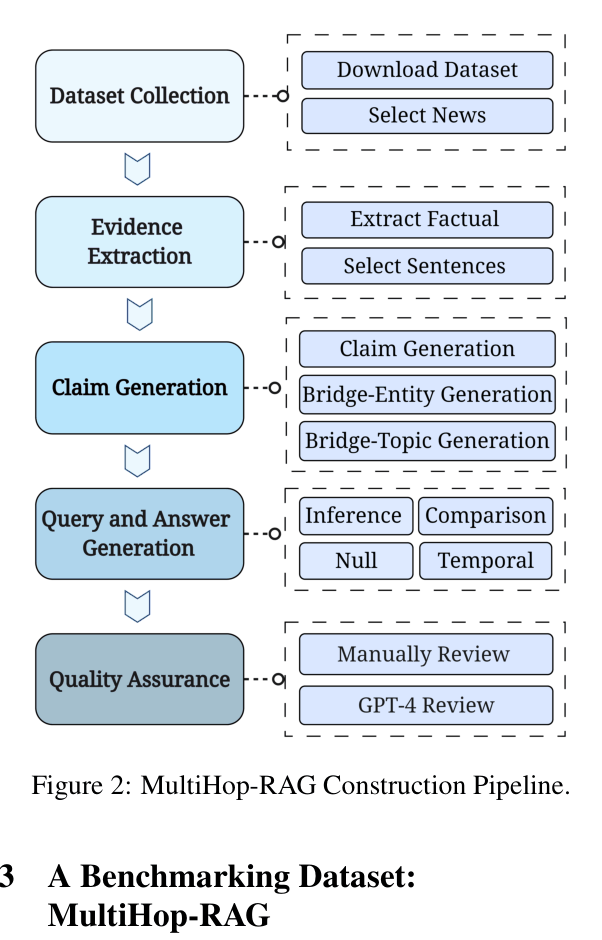
The data construction pipeline for MultiHop-RAG
Evaluation Highlights
- Standard embedding models struggle significantly: the best model (Voyage-02) achieves only 0.7467 Hits@10 even with re-ranking
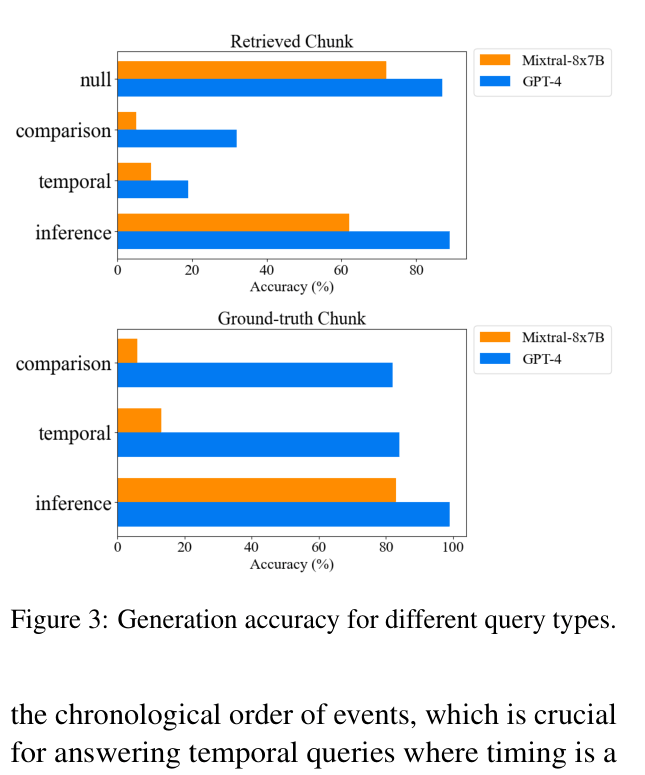
- LLM reasoning is a major bottleneck: Llama-2-70b achieves only 28% accuracy on multi-hop queries using retrieved chunks
- GPT-4 dominates reasoning tasks with 89% accuracy when given ground-truth evidence, while open-source models like Mixtral-8x7B lag behind at 36%
Breakthrough Assessment
7/10
Provides a necessary and missing resource (multi-hop benchmark) that reveals significant gaps in current RAG systems. While the construction method is standard (LLM-generated), the focus on multi-hop retrieval is high-impact.