📊 Experiments & Results
Evaluation Setup
Comprehensive evaluation on standard NLP benchmarks (Base models) and open-ended generation (Chat models).
Benchmarks:
- MMLU (Multi-task Language Understanding)
- GSM8K (Grade School Math)
- MATH (Mathematics)
- HumanEval (Python Coding)
- MBPP (Python Coding)
- HellaSwag (Commonsense Reasoning)
Metrics:
- Accuracy (pass@1)
- Few-shot accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| DeepSeek LLM 67B (Base) demonstrates superior performance compared to LLaMA-2 70B across math, code, and general reasoning benchmarks. | ||||
| MMLU | Accuracy (5-shot) | 68.9 | 71.3 | +2.4 |
| GSM8K | Accuracy (8-shot) | 56.8 | 69.1 | +12.3 |
| MATH | Accuracy (4-shot) | 10.6 | 18.7 | +8.1 |
| HumanEval | pass@1 | 29.9 | 43.3 | +13.4 |
| DeepSeek LLM 7B (Base) significantly outperforms LLaMA-2 7B, especially in code and math. | ||||
| GSM8K | Accuracy (8-shot) | 14.6 | 39.4 | +24.8 |
| HumanEval | pass@1 | 12.8 | 26.8 | +14.0 |
Experiment Figures
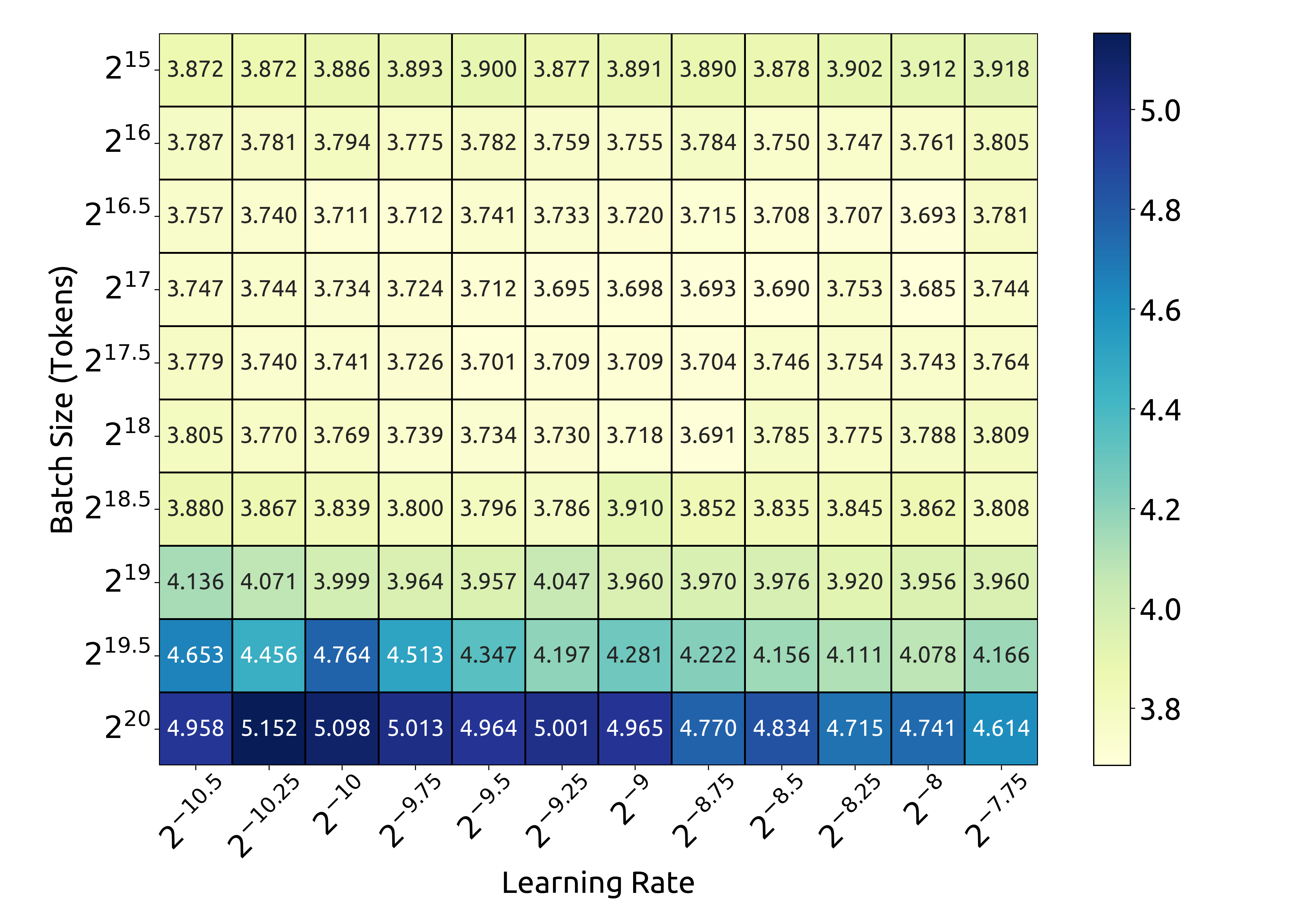
Optimal Batch Size and Learning Rate scaling with Compute Budget.
IsoFLOP curves and optimal model/data scaling fit.
Main Takeaways
- Scaling laws are sensitive to data quality: High-quality data favors scaling model size over data size for a fixed compute budget.
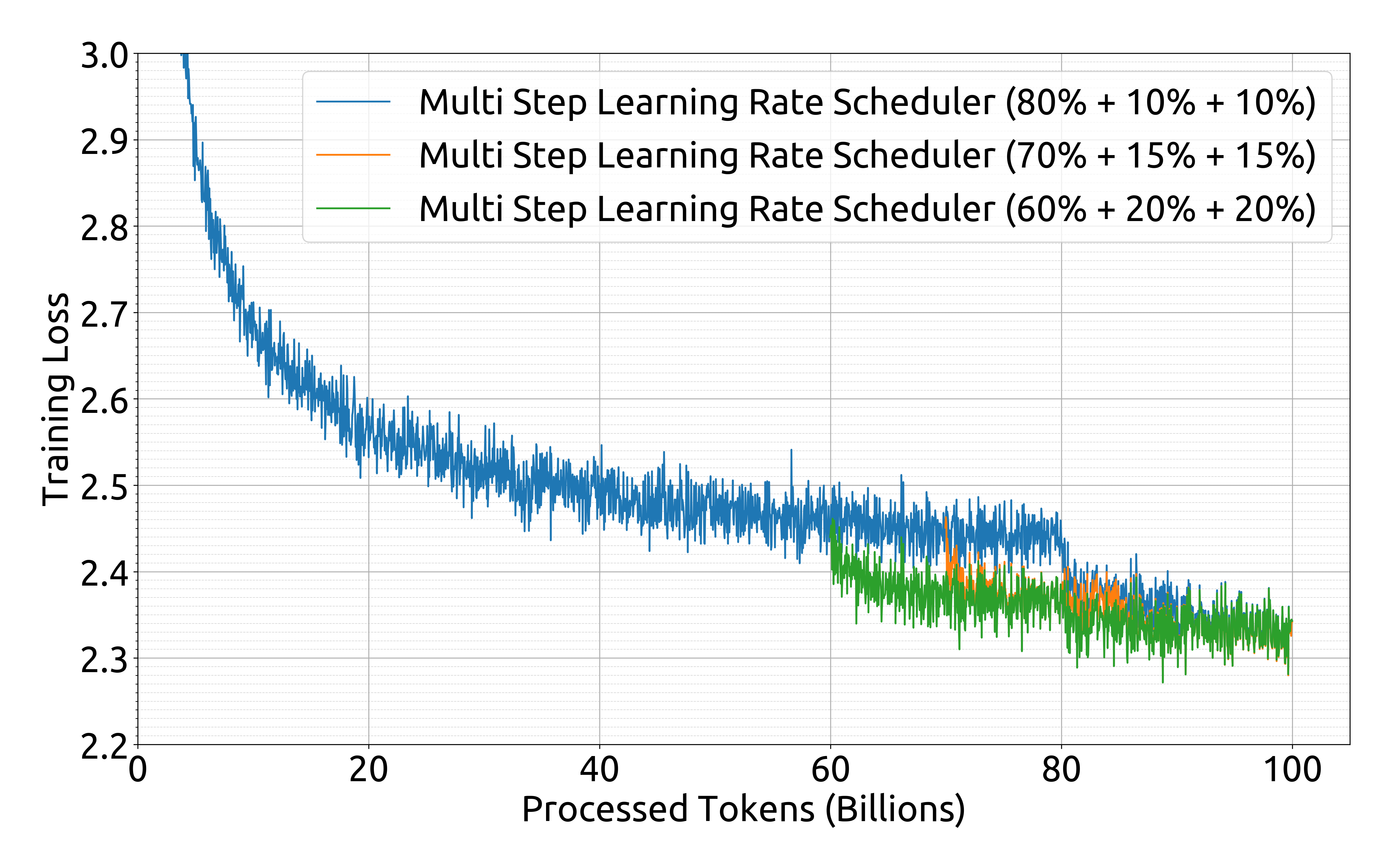
- Multi-step learning rate schedulers can achieve comparable performance to cosine schedulers while enabling easier continual training.
- DeepSeek 67B achieves SOTA performance among open-source models (at time of release), particularly excelling in mathematical reasoning and coding tasks compared to LLaMA-2.