📝 Paper Summary
Knowledge-Enhanced Pre-training
Entity Representation Learning
ConcEPT enhances language models by adding a pre-training objective that predicts the taxonomic concepts of entities mentioned in text, improving understanding of long-tail entities and their relationships.
Core Problem
Existing Pre-trained Language Models (PLMs) lack explicit conceptual knowledge, struggling to understand fine-grained concepts, concept hierarchies, and long-tail entities that appear infrequently in training data.
Why it matters:
- Humans rely on concepts (e.g., 'philosopher') to transfer knowledge from known entities (Plato) to unknown ones (Aristoxenus), a capability PLMs currently lack
- Current Knowledge-Enhanced PLMs often require cumbersome entity linking or modification during downstream tasks, limiting their practical usability
- PLMs treat rare entities as irrelevant tokens without recognizing their underlying conceptual class, leading to poor performance on knowledge-intensive tasks
Concrete Example:
Without conceptual knowledge, a model sees 'Aristoxenus' as just a rare token and fails to infer properties shared with 'Plato'. ConcEPT learns that both are 'philosophers', enabling knowledge transfer.
Key Novelty
Entity Concept Prediction (ECP) as a pre-training objective
- Introduces a new supervised task during pre-training: predicting the taxonomic concept (e.g., 'musician', 'philosopher') of an entity mention based solely on its context
- Utilizes a constructed taxonomy 'WikiTaxo' derived from Wikidata to provide ground-truth concept labels for millions of entities
- Aligns representations of different entities (e.g., Plato and Aristoxenus) under shared concept clusters in the vector space, simulating human-like categorization
Architecture
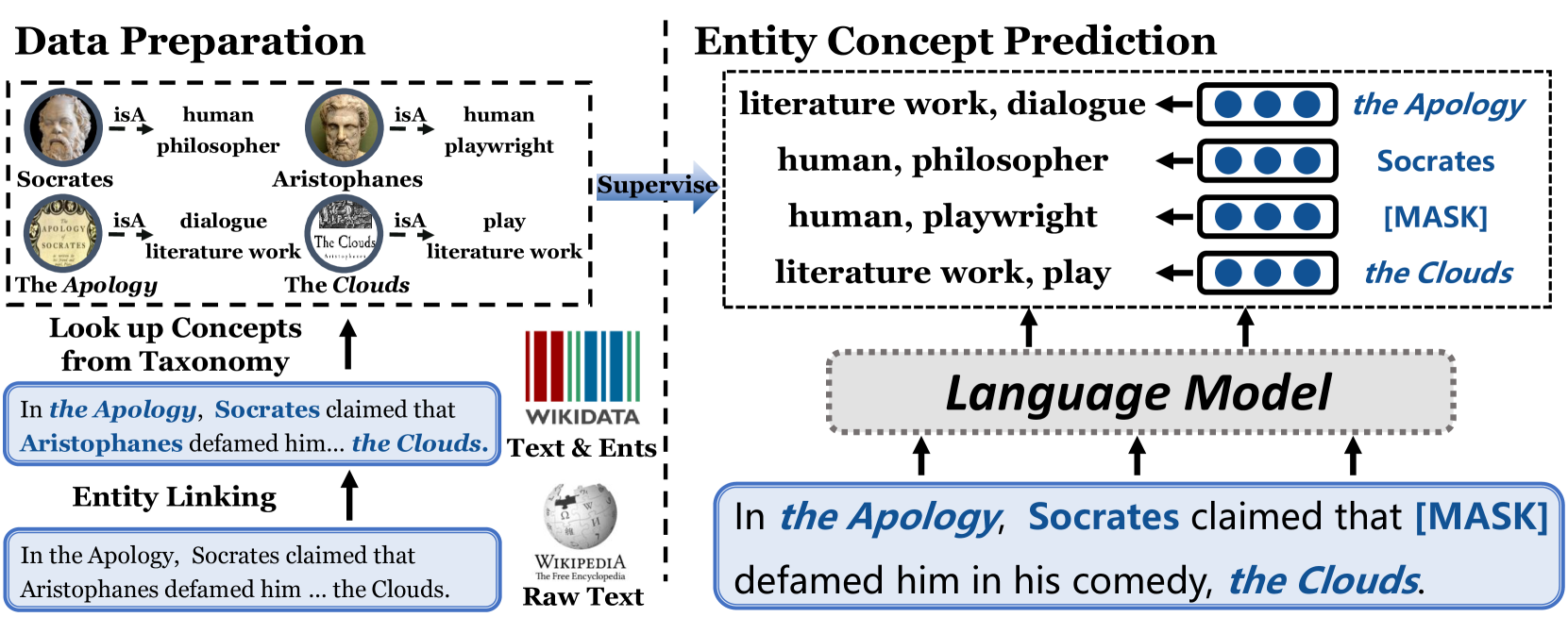
The pre-training framework of ConcEPT. It illustrates how an input sentence with entity mentions is processed.
Evaluation Highlights
- +2.8% Micro F1 improvement over vanilla BERT on the Open Entity entity typing benchmark
- Outperforms existing knowledge-enhanced models (like ERNIE and KEPLER) on fine-grained entity typing (FIGER dataset)
- +2.2% accuracy gain on Conceptual Property Judgment (CPJ) after fine-tuning, demonstrating improved acquisition of concept attributes
Breakthrough Assessment
7/10
Solid contribution to knowledge injection in PLMs. The method is simple, effective, and avoids complex pipeline changes for downstream users, though the core idea of concept prediction is an incremental step over entity linking objectives.